【Redis从入门到进阶】第 5 讲:Redis 实现缓存与缓存更新策略

标签: 【Redis从入门到进阶】第 5 讲:Redis 实现缓存与缓存更新策略 JavaScript博客 51CTO博客
2023-04-02 18:23:34 355浏览
本文已收录于专栏 ?《Redis从入门到进阶》?
专栏前言
本专栏开启,目的在于帮助大家更好的掌握学习Redis,同时也是为了记录我自己学习Redis的过程,将会从基础的数据类型开始记录,直到一些更多的应用,如缓存击穿还有分布式锁等。希望大家有问题也可以一起沟通,欢迎一起学习,对于专栏内容有错还望您可以及时指点,非常感谢大家 ?。
目录
- 专栏前言
- 1.什么是缓存?
- 2. 缓存的优缺点
- 3.为什么要Redis进行缓存
- 4. Redis 缓存流程
- 5.缓存的更新策略
- 6.主动更新策略
1.什么是缓存?
缓存大家肯定都听过,它是数据交换时的缓冲区(也叫Cache),是临时存放数据的区域。对于用户一些经常查询的数据,我们可以将其放在缓存中,因为缓存是在内存中的,查询的效率非常快,以此减少服务器向数据库请求的操作,减少数据库的压力,让用户页面访问的更快,提高用户体验。
2. 缓存的优缺点
听上去,缓存是一个非常好的东西,但其肯定也有缺点,如果我们应用不当,可能会出现各种问题。
- 优点:加快影响速度,减少数据库的压力
- 缺点:内存区域小,所以缓存不能存储太多数据。有可能出现缓存与数据库不一致的问题,内存区域容易丢失数据,维护成本较高。
3.为什么要Redis进行缓存
Redis是一个高性能的非关系型数据库,它的特性刚好就适合我们来进行缓存。
- 高性能:Redis 是内存数据库,数据都存在内存中,读写速度非常快,通常能够达到数十万次每秒的读写性能,比传统的关系型数据库快很多。因此,使用 Redis 作为缓存能够大大提高应用程序的性能。
- 可扩展性:Redis 可以非常容易地进行扩展,因为它支持主从复制和分布式集群,可以将数据分布在多个节点上,从而提高系统的容错性和可扩展性。
- 数据结构丰富:Redis 支持多种数据结构,包括字符串、哈希、列表、集合、有序集合等,这些数据结构的操作非常灵活和高效,能够满足不同应用场景的需求。
- 持久化:Redis 支持数据持久化,可以将数据保存到磁盘中,防止数据丢失。
- 生态圈丰富:Redis 有非常丰富的客户端库和工具,可以方便地集成到各种编程语言和框架中。同时,Redis 社区非常活跃,有大量的插件和扩展可以使用,方便了开发者的使用和维护。
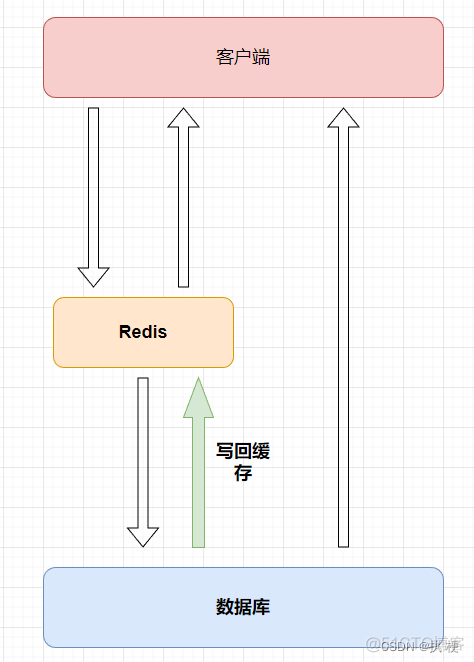
4. Redis 缓存流程
那么我们使用redis进行缓存的流程是怎么样呢?
首先我们的请求肯定是指向redis进行查询的,如果可以查到数据则直接返回,否则就继续将请求发送向数据库进行查找,如果可以找到则将数据返回并同时将该数据写入到缓存中,这样下次再请求该数据时就可以直接从缓存中找到。如果数据库也找不到就可以直接返回客户端了。下图是执行流程
代码实现,注意这里我们将对象转为JSON存入redis
@Override
public Result queryById(Long id){
String key="cache:shop"+id;
//1.从redis查询缓存
String shopJson=stringRedisTemplate.opsForValue().get(key);
//2.判断是否存在
if (StrUtil.isNotBlank(shopJson)){
//3.存在,直接返回
Shop shop=JSONUtil.toBean(shopJson,Shop.class);
return Result.ok(shop);
}
//4.不存在
Shop shop=getById(id);
//5.不存在,返回错误
if (shop==null){
return Result.fail("店铺不存在");
}
//6.存在,写入redis 同时设置过期时间
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),30L,TimeUnit.MINUTES);
return Result.ok(shop);
}5.缓存的更新策略
我们使用了redis实现了最基础的缓存效果,但我们还得了解缓存更新策略。因为redis的数据存储在内存,而内存是一片非常小的区域,我们如果只添加缓存而不删除或更新缓存,那数据肯定很快就存满了,而在更新的同时又有可能带来缓存与数据库数据不一致的情况,带来一定的维护成本。所以选择好的缓存更新策略是必不可少的,让我们来了解常见的缓存更新策略:
- 内存淘汰: 不用自己维护,利用
redis的内存淘汰机制,当内存不足时自动淘汰部分数据,下次查询时更新缓存。一致性差,没有维护成本。 - 超时剔除: 给缓存数据添加
TTL过期时间,到期后自动删除缓存,下次查询时更新缓存。一致性一般,维护成本低。 - 主动更新: 编写业务逻辑,在修改数据库的同时,更新缓存。一致性高,维护成本高。
那我们该如何选择呢 ? 这需要根据我们的业务场景需求来选择,如果对于一致性较低的场景,我们可以使用内存淘汰机制。对于高一致性需求的场景我们应该选择主动更新,并且以超时剔除为兜底方案,比如查询商品的数量。
6.主动更新策略
考虑到业务主要以数据一致性为主,我们这里讲的是最常用的主动更新策略,也就是由缓存的调用者,在更新数据库的同时更新缓存。当然这里面也有讲究,对于缓存我们选择删除缓存的更新策略,也就是每次更新数据库的同时让缓存失效,查询时再去更新,这样效率比较高。如果每次更新数据库我们都去更新缓存,更新了好多次才查询一次,那么无效写的操作就比较多了。
另外一个问题就是如何保证缓存与数据库的操作的同时成功或失败,这里我们可以将两个操作合并成一个事务,这里我们举例的是单体系统,不考虑分布式。为了保证数据一致性,在产生异常时我们需要手动进行回滚。
还有一个问题就是我们操作时到底是先操作数据库还是先操作缓存?有的人肯定有疑问,这有什么区别吗?在多个线程的情况下,如果我们是先操作缓存再操作数据库,由于数据库的操作时间相对于缓存来说是非常久的,此时就容易在操作数据库的时候进来一个线程去查询缓存,但此时缓存又被删了,于是后来的线程将数据库的是数据又写回缓存,而我们前面的线程又恰好将数据库修改了,那么这就会出现数据库与缓存不一致的问题。所以我们应该先操作数据库,再来删除缓存,这样出错的概率会小很多。
有关缓存与数据一致性问题坑比较多,我暂时也不太懂,以后有机会再聊。
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论