no12-springboot高并发第一次课-spring缓存和redis

分类: Java springboot 专栏: springboot学习 标签: 缓存
2023-03-29 22:24:43 1821浏览
spring cache
简单介绍
Spring Cache是一个框架,实现了基于注解的缓存功能。只需要简单地加一个注解,就能实现缓存功能。
Spring Cache提供了一层抽象,底层可以切换不同的cache实现。具体就是通过CacheManager接口来统一不同的缓
存技术。.
CacheManager是Spring提供的各种缓存技术抽象接口。
针对不同的缓存技术需要实现不同的CacheManager:
CacheManager | 描述 |
EhCacheCacheManager | 使用EhCache作为缓存技术 |
GuavaCacheManager | 使用Google的GuavaCache作为缓存技术 |
RedisCacheManager | 使用Redis作为缓存技术 |
操作步骤
- 1.引入依赖
对于springboot项目,只需要引入web启动器就会把spring-cache引入,所以不需要单独导cache的包
- 2.开启缓存开关
@SpringBootApplication
@EnableCaching
public class Ch7CacheApplication {- 3.基本用法
@RestController
@RequestMapping("user")
public class UserController {
@Resource
UserService userService;
//默认的缓存管理器用的是ConcurrentMapCacheManager,
//有点弊端就是,只要项目重启,之前缓存好的数据就全部丢失了。
@Resource
CacheManager cacheManager;
@GetMapping
@Cacheable(cacheNames = {"user"},key = "#root.targetClass+'.users'")
public List<User> getUsers(){
return userService.list();
}
@GetMapping("{id}")
// @Cacheable(cacheNames = "user",key = "{#root.args[0]}")
// @Cacheable(cacheNames = "user",key = "{#p0}")
// @Cacheable(cacheNames = "user",key = "{#a0}")
@Cacheable(cacheNames = "user",key = "{#id}")
public User getId(@PathVariable Integer id){
User byId = userService.getById(id);
return byId;
}
}
@CachePut(cacheNames = "user",key = "#user.id")
@PostMapping
public User add(@RequestBody User user){
userService.saveOrUpdate(user);
return user;
}
@PutMapping
@CachePut(cacheNames = "user",key = "#user.id")
public User update(@RequestBody User user){
userService.saveOrUpdate(user);
return user;
}
@DeleteMapping("{id}")
@CacheEvict(cacheNames = "user",key = "#id")
public void del(@PathVariable Integer id){
userService.removeById(id);
}添加缓存@Cacheable
cacheNames
或者可以直接写value,指定缓存组件的名字;将方法的返回结果放在哪个缓存中,是数组的方式,可以指定多个缓存
key
缓存数据使用的key;可以用它来指定。 默认是使用方法参数的值
编写SpEL; #id;参数id的值
#a0 #p0 #root. args[0]
keyGenerator
key的生成器;可以自己指定key的生成器的组件id
key/keyGenerator:二选一使用
同样也是例子:getEmp[2] 效果如下(跟上面是一样的)
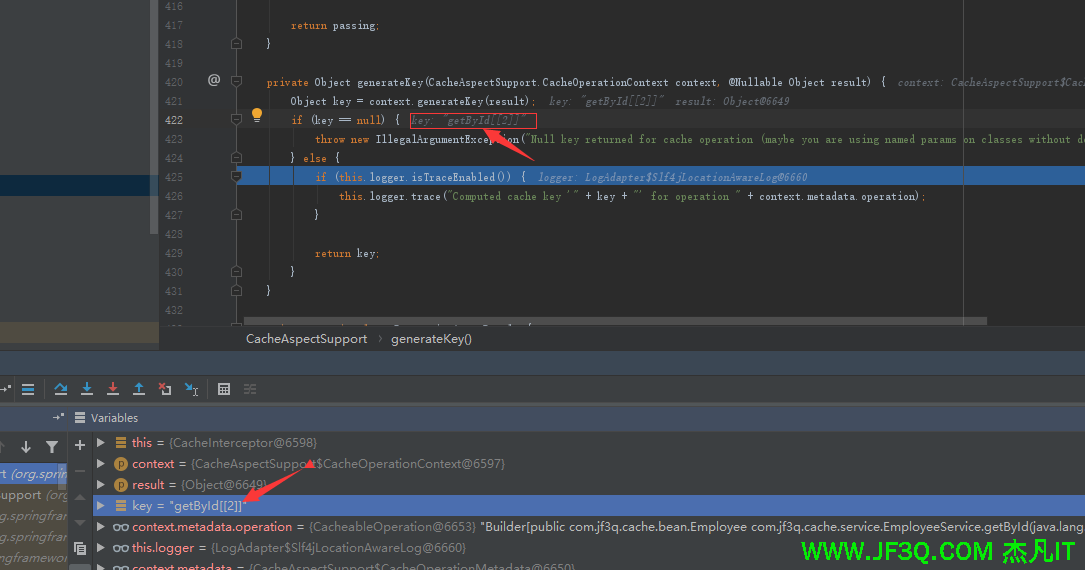
写法:
- 1.先写一个配置类
@Configuration
public class MyCacheConfig {
@Bean("mykeyGenerator")
public KeyGenerator keyGenerator(){
return new KeyGenerator() {
/**
* 生成目标key
* @param target
* @param method
* @param params
* @return
*/
@Override
public Object generate(Object target, Method method, Object... params) {
return method.getName()+"["+ Arrays.asList(params) +"]";
}
};
}
}- 2.service里引用
@Cacheable(value = {"emp"},keyGenerator = "mykeyGenerator")
public Employee getById(Integer id){
return employeeDao.getEmpId(id);
}condition
指定符合条件的情况下才缓存
例子:condition = "#a0>1" 就是说当一个参数大于1的时候才进行缓存
//这里的#a0也就是#id
@Cacheable(value = {"emp"},keyGenerator = "mykeyGenerator",condition = "#a0>1")
public Employee getById(Integer id){
return employeeDao.getEmpId(id);
}unless
否定缓存,可以理解成如果不是这样就进缓存。如果是这样就不进缓存
例子:unless = "#id ==2" 当传过来的id值是2的话就不进缓存。
@Cacheable(value = {"emp"},keyGenerator = "mykeyGenerator",condition = "#a0>1",unless = "#id ==2")
public Employee getById(Integer id){
return employeeDao.getEmpId(id);
}sync
是否使用异步模式。默认是false。当使用sync注解的时候,unless就不能用了。
更新缓存@CachePut
修改了数据库的某个数据,同时更新缓存
运行时机:1. 先调用目标方法;2.将目标方法的结果缓存起来。
@CachePut(cacheNames = "user",key = "#user.id")
@PostMapping
public User add(@RequestBody User user){
userService.saveOrUpdate(user);
return user;
}
@PutMapping
@CachePut(cacheNames = "user",key = "#user.id")
public User update(@RequestBody User user){
userService.saveOrUpdate(user);
return user;
}缓存清除@CacheEvict

@DeleteMapping("{id}")
@CacheEvict(cacheNames = "user",key = "#id")
public void del(@PathVariable Integer id){
userService.removeById(id);
}//同时清除多个缓存操作
@Caching(evict = {
@CacheEvict(value = {"category"}, key = "'test'"),
@CacheEvict(value = {"category"}, key = "'test1'")
})
//指定删除某个分区一下的所有数据
@CacheEvict(value = {"category"}, allEntries = true)
组合缓存规则@Caching
例子:根据名字查询员工后,让根据ID和根据email查询的时候也有缓存。
@Caching(
cacheable = {
@Cacheable(value = "emp",key = "#name")
},
put = {
@CachePut(value = "emp",key = "#result.id"),
@CachePut(value = "emp",key = "#result.email")
}
)
public Employee getByName(String name){
return employeeDao.getByName(name);
} @GetMapping("/getByName/{name}")
public Employee getByName(@PathVariable("name") String name){
return employeeService.getByName(name);
}抽取缓存的公共配置@CacheConfig
例子:service层或者controller层的方法上有很多缓存名字都是一样的,每个方法上都写一遍的话很麻烦。所以抽取个公共的比较好。
@CacheConfig(cacheNames = "emp") //加到service类上
@Caching(
cacheable = {
@Cacheable(/*value = "emp",*/key = "#name")
},
put = {
@CachePut(/*value = "emp",*/key = "#result.id"),
@CachePut(/*value = "emp",*/key = "#result.email")
}
)
public Employee getByName(String name){
return employeeDao.getByName(name);
}扩展知识点
1.list里的缓存更新问题
提出一个问题:如果删除或者修改或者新增一条数据后,list的缓存应该也随之变化,怎么解决?
思路:只要有增删改操作,就把list的缓存直接删掉!(一种简单粗暴的方式,你有什么更好的解决方案没)
@Resource
UserService userService;
@Resource
CacheManager cacheManager;
@GetMapping
@Cacheable(key = "#root.targetClass+'.users'")
public List<User> getUsers(){
return userService.list();
}
@GetMapping("{id}")
// @Cacheable(cacheNames = "user",key = "{#root.args[0]}")
// @Cacheable(cacheNames = "user",key = "{#p0}")
// @Cacheable(cacheNames = "user",key = "{#a0}")
@Cacheable(key = "{#id}")
public User getId(@PathVariable Integer id){
User byId = userService.getById(id);
return byId;
}
@PostMapping
@Caching(
evict = {
@CacheEvict(key = "#root.targetClass+'.users'"),
},
put = {
@CachePut(key = "#user.id"),
}
)
public User add(@RequestBody User user){
userService.saveOrUpdate(user);
return user;
}
@PutMapping
@Caching(
evict = {
@CacheEvict(key = "#root.targetClass+'.users'"),
},
put = {
@CachePut(key = "#user.id"),
}
)
public User update(@RequestBody User user){
userService.saveOrUpdate(user);
return user;
}
@DeleteMapping("{id}")
@Caching(evict = {
@CacheEvict(key ="#id"),
@CacheEvict(key = "#root.targetClass+'.users'"),
}
)
public Boolean del(@PathVariable Integer id){
return userService.removeById(id);
}2.springboot整合ehcache
需要引入的jar:
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.10.6</version>
</dependency>参考文章:
https://blog.51cto.com/binghe001/5243788
这里很方便设置回收策略
3.ehcache和spring cache的区别
https://www.jianshu.com/p/1fd282bc7d02
备注:ehcache和spring cache不是一回事哦!!!
分布式-redis缓存
只需要在上面的基础上做了小小的改动——在pom文件中把redis的启动器依赖导入即可将缓存管理器切换成redis。
以下内容全部属于新的扩展,总之各种扩展知识
问题1:序列化问题
- 1.传统的方式。利用jar包把对象转成json
- 2.redis默认的序列化机制是用的jdk序列化器,可以自定义改成json序列化器
1>先自定义配置类-将employee这个对象设置默认序列化机制为json序列化器
@Configuration
public class MyRedisConfig {
@Bean
public RedisTemplate<Object, Employee> empRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Employee> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer<Employee> serializer=new Jackson2JsonRedisSerializer<Employee>(Employee.class);
template.setDefaultSerializer(serializer);
return template;
}
}
2>编写测试类
关键是用RedisTemplate<Object, Employee> employeeRedisTemplate;而不是之前的RedisTemplate redisTemplate;
@Autowired
RedisTemplate<Object, Employee> employeeRedisTemplate;
@Test
public void test1(){
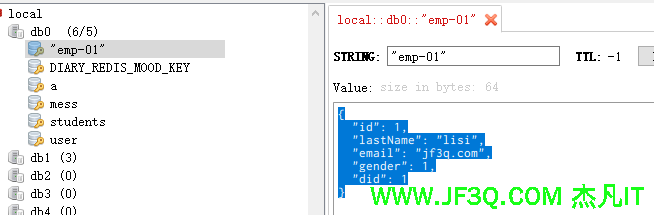
//给redis保存一个json对象
Employee employee= employeeDao.getEmpId(1);
employeeRedisTemplate.opsForValue().set("emp-01",employee);
}
效果如下:
问题2:缓存过期时间问题
真实企业做redis缓存的流程
- 引入redis的starter之后,容器中保存的是RedisCacheManager;
- RedisCacheManager帮我们创建RedisCache作为缓存组件(通过操作redis缓存数据)
- 保存对象的时候默认是jdk序列化方法,这里想改成json序列化器
springboot1.x版本的只做了解!!!
原理就是RedisCacheManager创建RedisCache的时候用的是RedisTemplate,重构下RedisCacheManager就行(这是针对springboot1.x版本-在SpringBoot1.x中,RedisCacheManager是可以使用RedisTemplate作为参数注入的)
然后在service层绑定一下选用哪个管理器就行@CacheConfig( cacheNames=" emp" , cacheManager ="employeeCacheManager" )
@Bean
public RedisTemplate<Object, Employee> empRedisTemplate(
RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Employee> template = new RedisTemplate<Object, Employee>();
template.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer<Employee> ser = new Jackson2JsonRedisSerializer<Employee>(Employee.class);
template.setDefaultSerializer(ser);
return template;
}
@Bean
public RedisTemplate<Object, Department> deptRedisTemplate(
RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Department> template = new RedisTemplate<Object, Department>();
template.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer<Department> ser = new Jackson2JsonRedisSerializer<Department>(Department.class);
template.setDefaultSerializer(ser);
return template;
}
//CacheManagerCustomizers可以来定制缓存的一些规则
@Primary //将某个缓存管理器作为默认的
@Bean
public RedisCacheManager employeeCacheManager(RedisTemplate<Object, Employee> empRedisTemplate){
RedisCacheManager cacheManager = new RedisCacheManager(empRedisTemplate);
//key多了一个前缀
//使用前缀,默认会将CacheName作为key的前缀
cacheManager.setUsePrefix(true);
return cacheManager;
}
@Bean
public RedisCacheManager deptCacheManager(RedisTemplate<Object, Department> deptRedisTemplate){
RedisCacheManager cacheManager = new RedisCacheManager(deptRedisTemplate);
//key多了一个前缀
//使用前缀,默认会将CacheName作为key的前缀
cacheManager.setUsePrefix(true);
return cacheManager;
}springboot2.x版本是重点掌握
针对springboot2.x版本-有很大的不同,RedisCacheManager构造器已经无法再使用RedisTemplate进行构造
所以这边的写法是:RedisTemplate不需要重构,只需要重构CacheManager就OK了
package com.jf3q.ch7cache.config;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.jsontype.impl.LaissezFaireSubTypeValidator;
import org.springframework.cache.CacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import javax.annotation.Resource;
import java.time.Duration;
@Configuration
public class MyRedisConfig {
@Resource
RedisConnectionFactory factory;
@Bean
public CacheManager cacheManager() {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance , ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// 配置序列化(解决乱码的问题)
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofDays(1))//设置过期时间
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
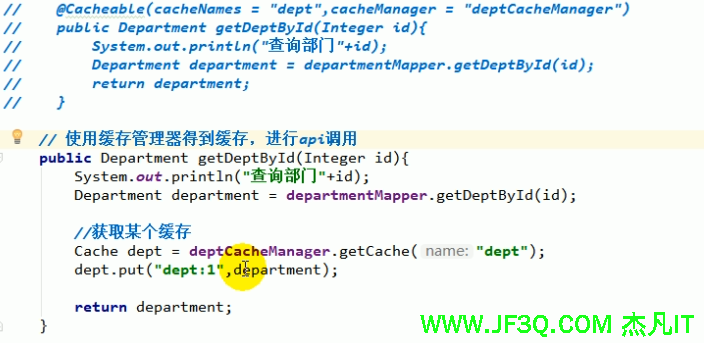
效果如下:

具体怎么写缓存注解的话,看上面的讲解
用编码的方式使用缓存:
redis介绍
Redis是目前使用最广泛的内存数据存储系统之一。它支持更丰富的数据结构,支持数据持久化、事务、HA高可用、双机集群系统,主从库。
Redis是Key-value存储系统。它支持的value类型包括String、List、Set、 Zset和hash。 这些数据都支持push/pop/add/remove,以及取交集、并集、差集、或更丰富的操作,而这些操作都是原子性的。
redis适合什么场景?
- 1.缓存
缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能.也提供了灵活的键淘汰策略,所以,现在Redis用在缓存的场合非常多
- 2.排行榜
很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
- 3.计数器
什么是计数器,如电商网站商品的浏览量、视频网站视频的播放数等。为了保证数据实时效,每次浏览都得给+1 ,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。Redis提供的incr命令来实现计数器功能,内存操作,性能非常好,非常适用于这些计数场景。
- 4.分布式会话
集群模式下,在应用不多的情况下一般使用容器 自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务, session不再由容器管理,而是由session服务及内存数据库管理。
- 5.分布式锁
很多互联网公司中都使用了分布式技术,分布式技术带来的技术挑战是对同一个资源的并发访问,如全局ID、减库存、秒杀等场景,并发量不大的场景可以使用数据库的悲观锁、乐观锁来实现,但在并发量高的场合中,利用数据库锁来控制资源的并发访问是不太理想的,大大影响了数据库的性能。可以利用Redis的setnx功能来编写分布式的锁,如果设置返回1说明获取锁成功。否则获取锁失败,实际应用中要考虑的细节要更多。
- 6.社交网络
点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据, Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。
- 7.最新列表
Redis列表结构, LPUSH可以在列表头部插入一个内容ID作为关键字, LTRIM可用来限制列表的数量,这样列表永远为N个ID ,无需查询最新的列表,直接根据ID去到对应的内容页即可。
- 8.消息系统
消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、 Kafka等流行的消息队列中间件,主要用于业务解耦、流星削峰及异步处理实时性低的业务。Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。另外,这个不能和专业的消息中间件相比。
redis的五种数据类型
Redis支持五种数据类型: string (字符串) , hash(哈希) , list(列表) , set(集合)及zset(sorted
set:有序集合)。
- 1.String (字符串)
string是redis 最基本的类型,你可以理解成与Memcached 一模一样的类型,一个 key对应一个 value.string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象(实体类上必须实现序列化)。
string类型是Redis最基本的数据类型, string 类型的值最大能存储512MB.
常用命令:set, get, decr, incr, mget等。
注意:一个键最大能存储512MB.
- 2.Hash(哈希)
Redis hash是一个键值(key=>value)对集合 ;是一个string类型的field和value的映射表, hash特别适合用于存储对象。
每个hash可以存储232-1键值对(40多亿)。
常用命令: hget. hset. hgetall等。
应用场景:存储一些结构化的数据.比如用户的昵称、年龄、性别、积分等,存储一个用户信息对象数据。
- 3.List (列表)
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边).
list类型经常会被用于消息队列的服务,以完成多程序之间的消息交换。
常用命令: Ipush. rpush. lpop. rpop. Irange等。
列表最多可存储232- 1元素(4294967295,每个列表可存储40多亿)。
- 4.Set(集合)
Redis的Set是string类型的无序集合。和列表一样,在执行插入和删除和判断是否存在某元素时,效率是很高的。集合最大的优势在于可以进行交集并集差集操作。Set可包含的最大元素数量是4294967295.集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
应用场景:
1.利用交集求共同好友。
2.利用唯-性,可以统计访问网站的所有独立IP。
3.好友推荐的时候根据tag求交集,大于某个threshold (临界值的)就可以推荐。
常用命令: sadd、spop、 smembers. sunion等。
集合中最大的成员数为232 - 1(4294967295,每个集合可存储40多亿个成员)。
- 5.zset(sorted set :有序集合)
Redis zset和set一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。 redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。sorted set是插入有序的,即自动排序。
常用命令: zadd、zrange、 zrem、 zcard等。
查询所有:zrange xxx 0 -1
查询某个成员的分数:zscore xxx yyy
当你需要-一个有序的并且不重复的集合列表时,那么可以选择sorted set数据结构。
应用举例:
(1 )例如存储全班同学的成绩,其集合value可以是同学的学号,而score就可以是成绩。
(2)排行榜应用,根据得分列出topN的用户等。
redis的基本命令简单练习
- 1.string类型
添加一个string类型的键值对用set命令,获取一个string类型的键值对用get命令

- 2.list类型
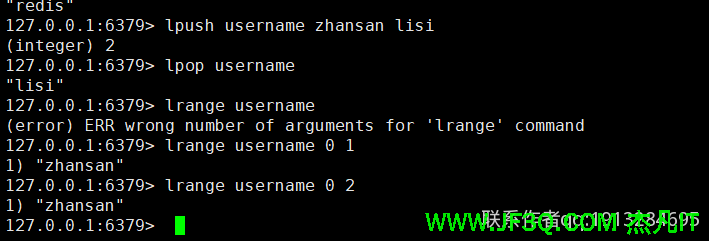
按元素的插入顺序存储,并且支持在list的左右两端插入/删除元素。元素可重复,list类型可以 实现简单消息队列的功能
lpush(左侧插入),lpop(左侧删除),rpush(右侧插入),rpop(右侧删除)命令用于操作list类型的key
如果不想删除元素,只想查看list中有哪些元素,则可以使用lrange命令。
- 3.set类型
元素无序不重复的集合,添加元素用sadd,删除用srem,查看集合中所有元素用smembers命令。
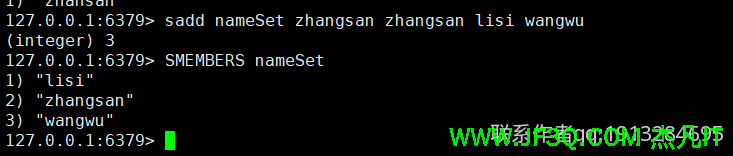
- 4.zset类型
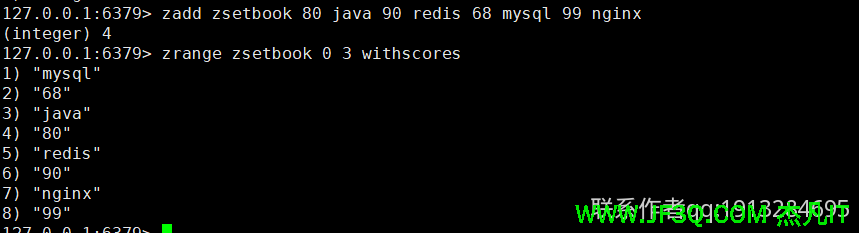
是有序不重复集合,每个元素都有一个分数,集合按分数排序,添加元素时如果元素已存在,则覆盖之前的分数,Zset类型非常 适合用于实现一些网站的排行榜功能
zrange按从小到大的顺序排序,再返回start到end之间的元素,传入withscores会返回分数
查询所有:zrange xxx 0 -1
查询某个成员的分数:zscore xxx yyy
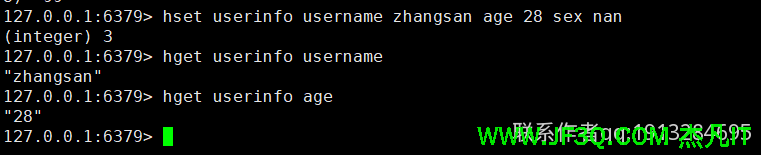
- 5.hash类型
适合存储对象,设值hset 取值hget
- 6.清空所有数据
FLUSHALL
java操作redis
- RedisTemplate
Spring封装了RedisTemplate来操作Redis,它支持所有的Redis原生的API。在RedisTemplate中定义了5中数据接口的操作方法。
1.opsForValue():操作字符串。
2.opsForHash():操作散列(是一个String类型的filed和value的映射表,hash特别适合用于存储对象,value中放的是结构化对象)。
3.opsForList( ):操作列表(是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部或尾部)。
4.opsForSet( ):操作集合(set是存放不重复值的集合,利用set可以做全局去重的功能,还可以进行交集并集差集等操作。
5.opsForZset( ):操作有序集合。
思考:redis可能会存在的问题:缓存击穿,缓存穿透,缓存雪崩?
总结:当你的redis数据库里面本来存的是字符串数据或者你要存取的数据就是字符串类型数据的时候,那么你就使用StringRedisTemplate即可,
但是如果你的数据是复杂的对象类型,而取出的时候又不想做任何的数据转换,直接从Redis 里面取出一一个对象,那么使用RedisTemplate是更好的选择。
redis的三种集群方式
redis有三种集群方式:主从复制,哨兵模式和集群
1.主从复制
- 主从复制原理:
●从服务器连接主服务器,发送SYNC命令;
●主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
●主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期问继续记录被执行的写命令;
●从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
●主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令; .
●从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令; (从服务器初始化完成)
●主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令(从服务器初始化完成后的操作)
- 主从复制优缺点:
优点:
●为了分载Master的读操作压力, Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成
●Slave同样可以接受其它Slaves的连接和同步请求 ,这样可以有效的分载Master的同步压力。
●支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
● Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
●Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据
缺点:
●Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写清求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
●主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题 ,降低了系统的可用性。
●Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
2.哨兵模式
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。为此, Redis2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行,
(2)主服务器出现故障时自动将从服务器转换为主服务器。
- 哨兵模式的优缺点
优点:
●哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
●主从可以自动切换,系统更健壮,可用性更高。
缺点:
●Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
3.Redis-Cluster集群
redis的哨兵模式基本已经可以实现高可用,读写分离, 但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
Redis-Cluster采用无中心结构,它的特点如下:
●所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
●节点的fail是通过集群中超过半数的节点检测失效时才生效。
●客户端与redis节点直连,不需要中间代理层,客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
工作方式:
在redis的每一个节点上, 都有这么两个东西, 一个是插槽(slot) ,它的的取值范围是:0-16383, 还有一个就是cluster ,可以理解为是-个集群管理的播件。当我们的存取的key到达的时候, redis会根据crc16的算法得出一个结果, 然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用, redis-cluster体群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
回顾下mybatis的缓存
需要引入的依赖:(这个依赖其实在spring cache或者redis缓存的时候也可以提前引入进来)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>一级缓存测试的话(需要开启事务,在springboot的话就是要一个注解@Transactional)
二级缓存开启:
mybatis-plus.configuration.cache-enabled=true
@Mapper
@CacheNamespaceRef(UserMapper.class)
public interface UserMapper extends BaseMapper<User> {
<!-- 在每个mapper映射文件中加-->
<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024">
</cache>参考文章:
https://blog.csdn.net/weixin_42855525/article/details/126937967
提一下前端缓存
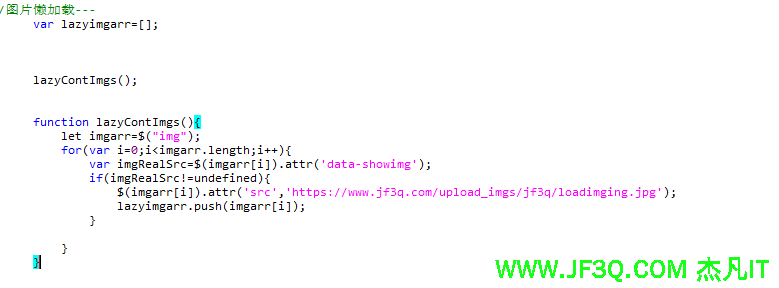
懒加载
- 后端部分代码
o.setContentDetails(o.getContentDetails().replace("src", "data-showimg"));- 前端部分代码

好博客就要一起分享哦!分享海报
此处可发布评论
评论(3)展开评论



 新业务
新业务  springboot学习
springboot学习  ssm框架课
ssm框架课  vue学习
vue学习  【带小白】java基础速成
【带小白】java基础速成 