第九章:Spring Boot 整合Spring Cache

分类: springboot 专栏: springboot3.0新教材 标签: 缓存学习
2024-01-19 00:55:21 2069浏览
springcache简介
基本概念
对一些更新不是很频繁的数据(但是查询很频繁),如果每次访问都从数据库中重新查询,则会比较耗费资源,可以考虑将这些数据在首次访问时从数据库中查询出来,然后存入缓存,再次访问时就不需要重复查询数据库,直接从缓存中读取出来,既省资源速度又快。
Spring Cache 是Spring 提供的一整套缓存解决方案,但它本身不是一种具体的缓存实现技术,Spring 提供了CacheManager 和Cache 接口统一不同的缓存技术。其中CacheManager是Spring 提供的各种缓存技术的抽象接口。而Cache 接口包含缓存的各种操作。
引入Spring Cache
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>然后启动类上加一个注解:@EnableCaching
Spring Cache常用注解和实例
常用注解
1. @Cacheable
可以标记在一个方法上,也可以标记在一个类上。当标记在一个方法上时表示该方法是支持缓存的,当标记在一个类上时则表示该类所有的方法都是支持缓存的。对于一个支持缓存的方法,Spring 会在其被调用后将其返回值缓存起来,以保证下次利用同样的参数来执行该方法时可以直接从缓存中获取结果,而不需要再次执行该方法。Spring 对缓存方法的返回值是以键值对进行缓存的,值就是方法的返回结果,键可以是方法的参数等。当一个支持缓存的方法在对象内部被调用时不会触发缓存功能的。@Cacheable 可以指定三个属性,value、key 和condition。
value 属性指定Cache 名称,也叫缓存的命名空间,表示当前方法的返回值是会被缓存在哪个Cache 上的。Value的值可以为单个字符串,也可以是数组。若为数组时,则表示指定多个Cache
直接上案例,用mybatisPlus做一个demo,先做查询所有图书的缓存
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(value = "book")
public class Book implements Serializable {
@TableId(value = "id",type = IdType.AUTO)
private Integer id;
private String bookName;
private Double price;
private String category;
private Integer pnum;
private String imgurl;
private String description;
private String author;
private Integer sales;
}@Cacheable(value = "books")
// @Cacheable(value ={"books1","books2"})
public List<Book> getlist() {
return bookDao.selectList(null);
}key 属性用来指定存储方法的返回结果时对应的键,该属性支持SpringEL 表达式。当没有指定该属性时, Spring 将使用默认策略生成key 。默认的key 生成策略是通过KeyGenerator 生成的,其默认策略如下:如果方法没有参数,则使用0 作为key。如果只有一个参数的话则使用该参数作为key。如果参数多于一个的话则使用所有参数的hashCode 作为key。除了默认策略还可以自定义策略生成key,自定义策略是指可以通过Spring 的EL 表达式来指定key。这里的EL 表达式可以使用方法参数及它们对应的属性。使用方法参数时我们可以直接使用“#参数名”或者“#p 参数index”#p0 表示方法的第一个参数,#p1 表示第二个参数,
上案例,根据id查书籍
// @Cacheable(value = "book", key = "#id")//使用 # 参数名
@Cacheable(value = "book", key = "#p0")//使用 #p 参数index
public Book getBookById(Integer id) {
return bookDao.selectById(id);
}
// @Cacheable(value = "book",key="#book.id")
@Cacheable(value = "book",key="#p0.id")
public Book getBookBy(Book book) {
return bookDao.selectById(book.getId());
}提示:这种缓存注解放到controller层也是可以的
除了上述使用方法参数作为key 之外,Spring 还提供了一个root 对象可以用来生成key。通过该root 对象可以获取到下表所示信息。

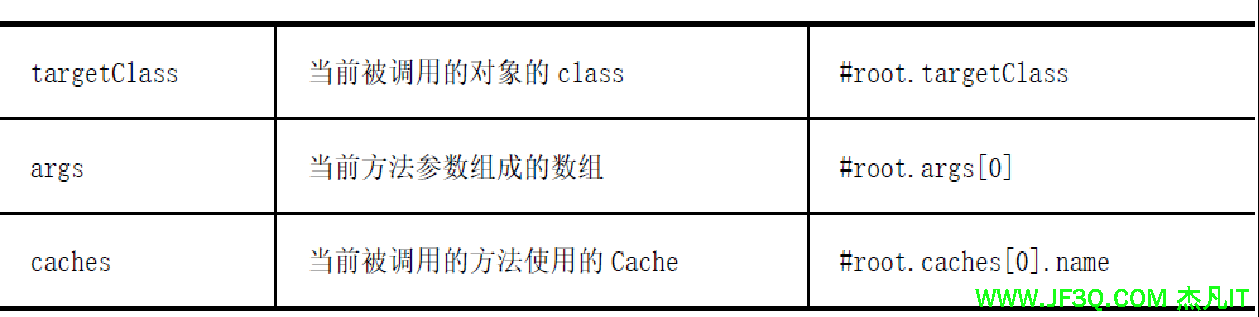
当要使用root 对象的属性作为key 时也可以将“#root”省略,因为Spring 默认使用的就是root 对象的属性
@Cacheable(value = "book",key="#root.targetClass+'userlist'")
// @Cacheable(value ={"book","book1"})
public List<Book> getList(){
return bookService.list();
}怎么监视缓存里的东西,
@Resource
CacheManager cacheManager;
用来指定缓存发生的条件,有时并不希望缓存一个方法所有的返回结果,可以通过condition 属性可以实现这一功能。condition 属性默认为空,表示将缓存所有的调用情形。其值是通过SpringEL 表达式来指定的,当为true 时表示进行缓存处理;当为false 时表示不进行缓存处理,即每次调用该方法时该方法都会执行一次。如下示例表示只有当id 为偶数时才会进行缓存
@Cacheable(value = "book",key="#id",condition = "#id%2==0")
public Book getById(@PathVariable Integer id){
// return bookService.getBookById(id);
return bookService.getById(id);
}2. @CacheEvict
是用来标注在需要清除缓存元素的方法或类上的。当标记在一个类上时表示其中所有的方法的执行都会触发缓存的清除操作。
@CacheEvict 可以指定的属性有value、key、condition、allEntries 和beforeInvocation。其中value、key 和condition 的语义与@Cacheable对应的属性类似。即value 表示清除操作是发生在哪些Cache 上的(对应Cache 的名称);key 表示需要清除的是哪个key,如未指定则会使用默认策略生成的key;condition 表示清除操作发生的条件。下面介绍一下新出现的两个属性allEntries 和beforeInvocation
allEntries 是boolean 类型,表示是否需要清除缓存中的所有元素。默认为false,表示不需要。当指定了allEntries 为true 时,Spring Cache 将忽略指定的key。有的时候我们需要Cache 一下清除所有的元素,这比一个一个清除元素更有效率。
一个一个删除的情况
@CacheEvict(value="book",key="#id") //根据参数指定的键来删除缓存
@DeleteMapping("/{id}")
public String deleteBook(@PathVariable Integer id){ //根据id号删除一本书, 同时删除缓存
System.out.println("从数据库删除一本书,同时删除key为"+id+"的缓存");
// bookService.removeById(id);
return "删除成功";
}全部删除的情况
@CacheEvict(value="book",key="#id",allEntries = true) 3. @CachePut注解
@PutMapping
@CachePut(value="book",key="#book.id")//修改缓存
public Book updateBook(@RequestBody Book book){ //修改一本书
System.out.println("从数据库修改一本书,同时修改缓存,key为"+book.getId());
bookService.saveOrUpdate(book);
return book;
}
4. @Caching 注解
可以在一个方法或者类上同时指定多个Spring Cache 相关的注解。其拥有三个属性:cacheable、put 和evict,分别用于指定@Cacheable、@CachePut 和@CacheEvict
举例:我们修改了某个book。那之前查询所有book的那个缓存,是不是应该更新一下?
@Caching(
put=@CachePut(value="book",key="#book.id"),
evict = @CacheEvict(value ="book",key="#root.targetClass+'userlist'" )
)5. @CacheConfig
有很多缓存名字都是一样的,每个方法上都写一遍的话很麻烦。所以抽取个公共的比较好。
@CacheConfig(cacheNames = "book")//cacheNames就是缓存名,跟value是等价的
public class BookController {
补充:每次写key比较麻烦,咱们可以弄一个生成key的规则出来
示例完整代码
查看图书详情时,如果缓存中有数据,就从缓存中读取数据,否则从数据库中查询,如果添加一本新书,同样数据存入缓存,再次查询时将从缓存中读取,如果删除一本书,从数据库删除的同时如果缓存中也有数据一并删除。
Spring Cache 采用默认缓存实现技术,Dao 层采用mybatisPlus。
@RestController
@RequestMapping("/book")
public class BookController {
@Autowired
BookService bookService;
@Resource
CacheManager cacheManager;
@GetMapping("/list")
@Cacheable(value = "book",key="#root.targetClass+'userlist'")
// @Cacheable(value ={"book","book1"})
public List<Book> getList(){
return bookService.list();
}
@GetMapping("/{id}")
@Cacheable(value = "book",key="#id",condition = "#id%2==0")
public Book getById(@PathVariable Integer id){
// return bookService.getBookById(id);
return bookService.getById(id);
}
@CacheEvict(value="book",key="#id",allEntries = true) //根据参数指定的键来删除缓存
@DeleteMapping("/{id}")
public String deleteBook(@PathVariable Integer id){ //根据id号删除一本书, 同时删除缓存
System.out.println("从数据库删除一本书,同时删除key为"+id+"的缓存");
// bookService.removeById(id);
return "删除成功";
}
@PutMapping
@Caching(
put=@CachePut(value="book",key="#book.id"),
evict = @CacheEvict(value ="book",key="#root.targetClass+'userlist'" )
)
// @CachePut(value="book",key="#book.id")//修改缓存
public Book updateBook(@RequestBody Book book){ //修改一本书
System.out.println("从数据库修改一本书,同时修改缓存,key为"+book.getId());
bookService.saveOrUpdate(book);
return book;
}
}使用Redis做缓存
//有点弊端就是,只要项目重启,之前缓存好的数据就全部丢失了。使用流程
- 引入redis的启动器依赖,然后配置指定缓存类型为Redis
spring:
cache:
#指定缓存类型为redis
type: redis
redis:
# 指定redis中的过期时间为1h,默认ttl为-1永不过期
time-to-live: 3600000
#key-prefix: CACHE_ #缓存key前缀,一般不推荐
#use-key-prefix: true #是否开启缓存key前缀,一般不配置
cache-null-values: true #缓存空值,解决缓存穿透问题- 建议修改下序列化问题
缓存默认使用jdk 进行序列化(可读性差),自定义序列化方式为JSON 需要编写配置类
@Configuration
public class RedisConfig {
@Bean
public RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
//获取到配置文件中的配置信息
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//指定缓存序列化方式为json
config = config.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//设置配置文件中的各项配置,如过期时间
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {//prefixKeysWith
config = config.prefixCacheNameWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}缓存击穿-缓存雪崩-缓存穿透
- 缓存雪崩(Cache Avalanche): 当缓存中的大量数据在同一时间失效或被清除,而对这些数据的请求同时涌入数据库时,数据库会承受巨大的压力,导致数据库性能下降甚至宕机。这种情况称为缓存雪崩。通常,缓存雪崩是由于缓存设置了相同的过期时间或者缓存服务器故障导致的。为了避免缓存雪崩,可以使用随机的过期时间、设置热点数据永不过期、使用多级缓存等方法。
- 缓存击穿(Cache Breakdown): 当一个非常热门的数据(缓存中不存在)在缓存过期的瞬间,有大量并发请求到达,导致请求绕过缓存直接访问数据库,此时数据库可能就会承受过大的压力。这种情况被称为缓存击穿。为了避免缓存击穿,可以使用互斥锁或者分布式锁来控制对数据库的并发访问,保证只有一个线程能够访问数据库,并将查询结果设置到缓存中。
- 缓存穿透(Cache Penetration): 缓存穿透是指发起查询一个不存在于缓存和数据库中的数据,这样的查询会直接穿透缓存访问数据库。恶意的攻击者可以通过构造大量不存在的请求来压垮数据库。为了避免缓存穿透,可以在缓存中设置空值或者布隆过滤器等机制来过滤无效的请求。
总结:为了避免缓存雪崩、缓存击穿和缓存穿透,可以采取一些策略,如设置合理的缓存过期时间、使用多级缓存、使用互斥锁或分布式锁、设置空值缓存、使用布隆过滤器等。同时,根据具体场景和需求,还需要综合考虑缓存的容量、性能和一致性等因素来进行合理的缓存设计。
复杂条件查询时的缓存
- 分析:
动态查询图书时,条件是动态的,但仍有可能多次查询中,后面的查询使用了跟前面一样的条件,这时缓存就可以有用武之地了。但这种存储缓存和获取缓存都比较复杂,主要是key 的设计比较复杂,因为它可能包含多个不确定的属性在上述rediscache 项目的基础上动态查询图书信息,实现不同组合的查询条件均有缓存功能
添加方法实现动态查询,还有关键一点是在方法上面添加@Cacheable注解,其中的键采用拼接的方式,当查询条件(对象)的某一个属性不为空时就拼接比如,如果从前端传递过来的封装了查询条件的Book 对象(condition)的name 属性的值是“a”,category 的属性的值是”计算机“,而author 属性的值是NULL,这时缓存中的键、就是“ a 计算机”,查出来的值就会以这个键名存储到缓存名称为“books”的缓存中去。
@Cacheable(key="(#condition.bookName!=null?#condition.bookName:'')+(#condition.category!=null?#condition.category:'')+(#condition.author!=null?#condition.author:'')") //定义缓存的键为拼接的参数,值是方法的返回值
@PostMapping
public List<Book> searchBooks(@RequestBody Book condition){ //查找一本书
System.out.println("条件查询,并添加到缓存,key为搜索条件的组合");
System.out.println("condition:"+condition);
LambdaQueryWrapper<Book> queryWrapper= new LambdaQueryWrapper<>();
if (StringUtils.hasText(condition.getBookName())) {
queryWrapper.like(Book::getBookName,condition.getBookName());
}
if (StringUtils.hasText(condition.getCategory())) {
queryWrapper.like(Book::getCategory,condition.getCategory());
}
if (StringUtils.hasText(condition.getAuthor())) {
queryWrapper.like(Book::getAuthor,condition.getAuthor());
}
return bookService.list(queryWrapper);
}自定义键生成策略
上面案例拼接的键实现起来比较麻烦,还有一种做法是自定义键生成策略,做法是将方法上面有@Cacheable 注解的key 属性替换为keygenerator 属性,同时在RedisConfig 中创建一个KeyGenerator 类型的Bean
@Bean
public KeyGenerator bookSearchGenerator(){
KeyGenerator keyGenerator=new KeyGenerator() {
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder sb = new StringBuilder();
// sb.append(target.getClass().getName());
// sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
}
};
return keyGenerator;
}这个方法就是自定义生成键的策略,这里是指把参数对象的调用了toString()方法后的字符串作为键,最后把这个Bean 赋值给@Cacheable 注解的keygenerator 属性。
@Cacheable(value="books",keyGenerator = "bookSearchGenerator") //定义缓存的键为自定义的键生成策略,值是方法的返回值
@PostMapping
public List<Book> searchBooks(@RequestBody Book condition){ //查找一本书
System.out.println("条件查询,并添加到缓存,key为搜索条件的组合");
System.out.println("condition:"+condition); LambdaQueryWrapper<Book> queryWrapper= new LambdaQueryWrapper<>();
if (StringUtils.hasText(condition.getBookName())) {
queryWrapper.like(Book::getBookName,condition.getBookName());
}
if (StringUtils.hasText(condition.getCategory())) {
queryWrapper.like(Book::getCategory,condition.getCategory());
}
if (StringUtils.hasText(condition.getAuthor())) {
queryWrapper.like(Book::getAuthor,condition.getAuthor());
}
return bookService.list(queryWrapper);
}再次测试
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论
您可能感兴趣的博客
 新业务
新业务  springboot学习
springboot学习  ssm框架课
ssm框架课  vue学习
vue学习  【带小白】java基础速成
【带小白】java基础速成 