13.一文彻底了解线程池

标签: 13.一文彻底了解线程池 Java博客 51CTO博客
2023-03-25 18:45:43 396浏览
大家好,我是王有志。关注王有志,一起聊技术,聊游戏,聊在外漂泊的生活。 最近搞了个交流群:共同富裕的Java人,核心功能是提供面试交流场所,分享八股文或面试心得,宗旨是“Javaer help Javaer”,希望能够借他人之经验,攻克我之面试,欢迎各位加入我们。
下面,我们开始今天的主题:线程池。线程池是面试中必问的八股文,我将涉及到到的问题分为3大类:
- 基础使用
- 线程池是什么?为什么要使用线程池?
- Executor框架是什么?
- Java提供了哪些线程池?
- 实现原理
- 线程池的底层原理是如何实现的?
- 创建线程池的参数有哪些?
- 线程池中的线程是什么时间创建的?
- 系统设计
- 如何合理的设置线程池的大小?
- 如果服务器宕机,怎么处理队列中的任务?
希望今天的内容能够帮你解答以上的问题。
Tips:
- 本文使用Java 11源码进行分析;
- 文章会在源码中添加注释,关键内容会有单独的分析。
池化思想
在你的编程生涯中,一定遇到过各种各样的“池”,如:数据库连接池,常量池,以及今天的线程池。无一例外,它们都是借助池化思想来管理计算机中的资源。
维基百科中是这样描述“池化”的:
In resource management, pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management.
“池化”指的是将资源汇聚到一起,以发挥优势或降低风险。
接着来看维基百科中对“池”的描述:
In computer science, a pool is a collection of resources that are kept, in memory, ready to use, rather than the memory acquired on use and the memory released afterwards.A pool client requests a resource from the pool and performs desired operations on the returned resource. When the client finishes its use of the resource, it is returned to the pool rather than released and lost.
计算机科学中的“池”,是内存中保存资源的集合,创建资源以备使用,停用时回收,而不是使用时创建,停用时丢弃。客户端从池中请求资源,并执行操作,当不再使用资源时,将资源归还到池中,而不是释放或丢弃。
为什么要使用“池”?
首先"池"是资源的集合,通过“池”可以实现对资源的统一管理;
其次,“池”内存放已经创建并初始化的资源,使用时直接从“池”内获取,跳过了创建及初始化的过程,提高了响应速度;
最后,资源使用完成后归还到“池”中,而非丢弃或销毁,提高资源的利用率。
线程池
池化思想的引入是为了解决资源管理中遇到的问题,而线程池正是借助池化思想实现的线程管理工具。那么线程池可以帮助我们解决哪些实际的问题呢?
最直接的是控制线程的创建,不加以限制的创建线程会耗尽系统资源。不信的话你可以试试下面的代码:
Tips:卡顿警告~~
其次,线程的创建和销毁是需要时间的,借助线程池可以有效的避免线程频繁的创建和销毁线程,提高程的序响应速度。
问题解答:线程池是什么?为什么要使用线程池?
Executor体系
Java中提供了功能完善的Executor体系,用于实现线程池。先来了解下Executor体系中的核心成员间的关系:
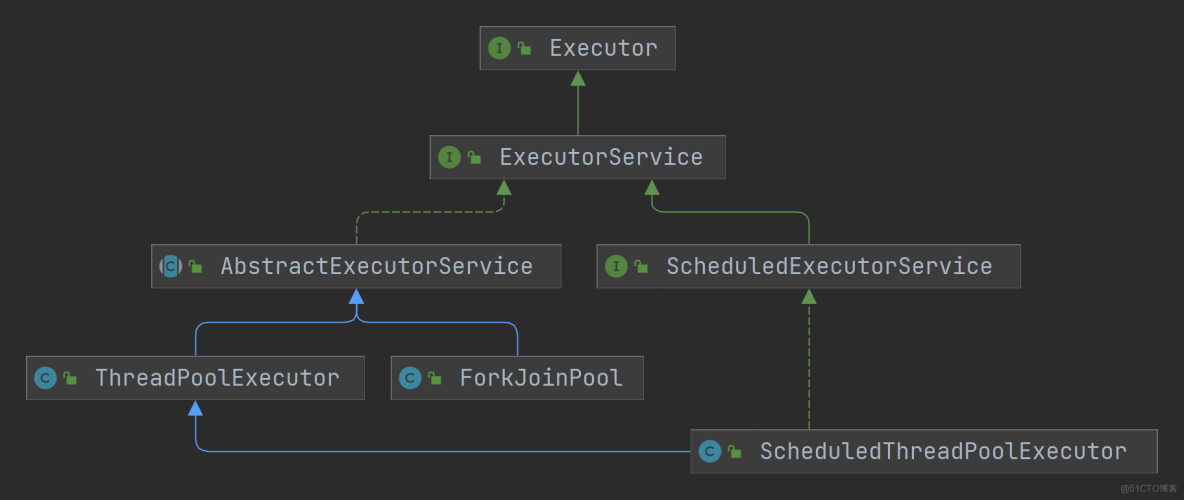
Executor体系的最顶层是Executor接口和ExecutorService接口,它们定义了Executor体系的核心功能。
Executor接口
Executor接口的注释:
An object that executes submitted Runnable tasks. This interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc. An Executor is normally used instead of explicitly creating threads.
Executor接口非常简单,只定义了execute方法,主要目的是将Runnable任务与执行机制(线程,调度任务等)解耦,提供了执行Runnable任务的方法。
ExecutorService接口
ExecutorService接口继承了Executor接口,拓展了Executor接口的能力。ExecutorService接口的注释:
An Executor that provides methods to manage termination and methods that can produce a Future for tracking progress of one or more asynchronous tasks.
ExecutorService接口关键方法的声明:
对关键方法做一个说明:
- 继承自
Executor接口:
-
execute:执行Runnable任务;
-
ExecutorService接口定义的方法:
-
submit:执行Runnable或Callable任务,并返回Future; -
shutdown:允许已提交的任务执行完毕,但不接受新任务的关闭; -
shutdownNow:尝试关闭所有任务(正在/等待执行),并返回等待执行的任务。
Tips:其余方法建议阅读源码中的注释,即便是提到的4个方法,也要阅读注释。
问题解答:Executor框架是什么?
ThreadPoolExecutor核心流程
Executor体系中,大家最熟悉的一定是ThreadPoolExecutor实现了,也是我们能够实现自定义线程池的基础。接下来逐步分析ThreadPoolExecutor的实现原理。
构造线程池
ThreadPoolExecutor提供了4个构造方法,我们来看参数最全的那个构造方法:
ThreadPoolExecutor的构造方法提供了7个参数:
-
int corePoolSize:线程池的核心线程数量,创建线程的数量小于等于corePoolSize时,会一直创建线程; -
int maximumPoolSize:线程池的最大线程数量,当线程数量等于corePoolSize后且队列已满,允许继续创建个线程;
-
long keepAliveTime:线程的最大空闲时间,当创建了超出corePoolSize数量的线程后,这些线程在不执行任务时能够存活的时间,超出keepAliveTime后会被销毁; -
TimeUnit unit:keepAliveTime的单位; -
BlockingQueue<Runnable> workQueue:阻塞队列,用于保存等待执行的任务; -
ThreadFactory threadFactory:线程工厂,用于创建线程,默认使用Executors.defaultThreadFactory()。 -
RejectedExecutionHandler handler:拒绝策略,当队列已满,且没有空闲的线程时,执行的拒绝任务的策略。
Tips:有些小伙伴会疑问,如果每次执行一个任务,执行完毕后再执行新任务,线程池依旧会创建corePoolSize个线程吗?答案是会的,后文解释。
问题解答:创建线程池的参数有哪些?
主控状态CTL与线程池状态
ThreadPoolExecutor中定义了主控状态CTL和线程池状态:
CTL包含了两部分内容:线程池状态(runState,源码中使用rs替代)和工作线程数(workCount,源码中使用wc替代)。当看到位运算符和“MASK”一起出现时,就应该想到应用了位掩码技术。
主控状态CTL的默认值是RUNNING | 0即:1110 0000 0000 0000 0000 0000 0000 0000。runStateOf方法返回低29位为0的CTL,与之对应的是线程池状态,workerCountOf方法则返回高3位为0的CTl,用低29位表示工作线程数量,所以线程池最多允许536870911个线程。
Tips:
- 工作线程指的是已经创建的线程,并不一定在执行任务,后文解释;
- 位运算的可以参考编程技巧:“高端”的位运算;
- Java中二进制使用补码,注意原码,反码和补码间的转换。
线程池的状态
注释中对线程池的状态做出了详细的说明:
RUNNING: Accept new tasks and process queued tasks SHUTDOWN: Don't accept new tasks, but process queued tasks STOP: Don't accept new tasks, don't process queued tasks, and interrupt in-progress tasks TIDYING: All tasks have terminated, workerCount is zero, the thread transitioning to state TIDYING will run the terminated() hook method TERMINATED: terminated() has completed
- RUNNING:接收新任务,处理队列中的任务;
- SHUTDOWN:不接收新任务,处理队列中的任务;
- STOP:不接收新任务,不处理队列中的任务,中断正在执行的任务;
- TIDYING:所有任务已经执行完毕,并且工作线程为0,转换到TIDYING状态后将执行Hook方法
terminated(); - TERMINATED:
terminated()方法执行完毕。
状态的转换
注释中也对线程池状态的转换做出了详细说明:
RUNNING -> SHUTDOWN On invocation of shutdown() (RUNNING or SHUTDOWN) -> STOP On invocation of shutdownNow() SHUTDOWN -> TIDYING When both queue and pool are empty STOP -> TIDYING When pool is empty TIDYING -> TERMINATED When the terminated() hook method has completed
我们通过一张状态转换图来了解线程池状态之间的转换:
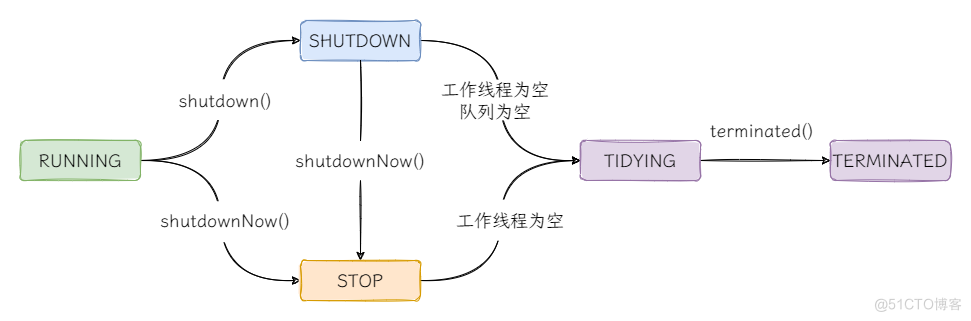
结合源码,可以看到线程池的状态从RUNNING到TERMINATED其数值是单调递增的,换句话说线程池从“活着”到“死透”所对应的数值是逐步增大,所以可以使用数值间的比较去确定线程池处于哪一种状态。
使用线程池
我们已经对ThreadPoolExecutor有了一个整体的认知,现在可以创建并使用线程池了:
这里我使用最“简单”的构造方法,我们看到在线程池中提交任务使用的是submit方法,该方法在抽象类AbstractExecutorService中实现:
submit的重载方法之间只有参数列表的差别,实现逻辑是相同的,均是先封装RunnableFuture对象,再调用ThreadPoolExecutor#execute方法。
问题解答:submit()和execute()方法有什么区别?
execute方法
继承自Executor接口的execute方法是线程池的关键方法:
阅读execute方法的源码时需要知道一个前提,addWorker方法会检查线程池状态和工作线程数量,并执行工作任务。接着来看execute方法的3种执行情况:
- STEP 1:线程池状态:RUNNING,工作线程数:小于核心线程数,此时执行
addWorker(command, true); - STEP 2:线程池状态:RUNNING,工作线程数:等于核心线程数,队列:未饱和,添加到队列中;
- STEP 3:线程池状态:RUNNING,工作线程数:等于核心线程数,队列:已饱和,执行
addWorker(command, false)。
需要重点关注STEP 1的部分,还记得构造线程池最后的问题吗?STEP 1便解释了为什么一个接一个的执行任务,依旧会创建出corePoolSize个线程。接着我们通过一张流程图展示execute方法的执行流程:

流程图画得比较“复杂”,因为有些判断看似在一行中执行,实际上是借助了&&运算符短路的特性来决定是否执行,例如isRunning(c) && workQueue.offer(command)中,如果isRunning(c) == false则不会执行workQueue.offer(command)。
addWorker方法
返回值为布尔类型表示是否成功执行,参数列表中有两个参数:
-
Runnable firstTask,待执行任务; -
boolean core,true表示最多允许创建corePoolSize个线程,false表示使用最多允许创建maximumPoolSize个线程。
在分析execute方法的过程中,我们提前“剧透”了addWorker方法的功能:
- 检查线程池状态和工作线程数量
- 执行工作任务
因此addWorker方法的源码部分我们分成两部分来看。
Tips:再次强调本文使用Java 11源码进行分析,在addWorker方法的实现上Java 11与Java 8存在差异。
检查线程池状态和工作线程数量
第一部分是线程池状态和工作线程数量检查的源码:
注释1的代码并不复杂,只是需要结合线程池在不同状态下的处理逻辑来分析:
- 当状态“至少”为SHUTDOWN时,什么情况不需要处理?
- 添加新的任务(对应条件2-2)
- 队列为空(对应条件2-3)
- 当状态“至少”为STOP时,线程池应当立即停止,不接收,不处理。
Tips:线程池状态的部分说线程池状态从RUNNING到TERMINATED是单调递增的,因此在Java 11的实现中才会出现runStateAtLeast方法。
执行工作任务
第二部分是执行工作任务的源码:
结合两部分代码,一个正向流程是这样的:
- 检查状态:检查是否允许创建
Worker,如果允许执行compareAndIncrementWorkerCount(c),CTL中工作线程数量+1; - 执行任务:创建
Worker对象,通过Worker对象获取线程,添加到workers中,最后启动线程。
回过头看我们之前一直提到的工作线程,实际上是Worker对象,我们可以近似的将Worker对象和工作线程画上等号。
问题解答:线程池中的线程是什么时间创建的?
三调addWorker
execute方法中,有3种情况调用addWorker方法:
- STEP 1:
addWorker(command, true) - STEP 2:
addWorker(null, false) - STEP 3:
addWorker(command, false)
STEP 1和STEP 3很好理解,STEP 1最多允许创建corePoolSize个线程,STEP 3最多允许创建maximumPoolSize个线程。STEP 2就比较难理解了,传入了空任务然后调用addWorker方法。
什么情况下会执行到addWorker(null, false)?
- 第1个条件:
。
- 第2个条件:
isRunning(c) && workQueue.offer(command) - 第3个条件:
workerCountOf(recheck) == 0
处于RUNNING状态的条件不难理解,矛盾的是第1个条件和第3个条件。根据这两个条件可以得到:
,也就是说允许创建核心线程数为0的线程池。
接着我们来看addWorker(null, false)做了什么?创建了Worker对象,添加到workers中,并调用了一次Thread.start,虽然没有任何待执行的任务。
为什么要创建一个Worker对象?别忘了,已经执行过workQueue.offer(command)了,需要保证线程池中至少有一个Worker,才能执行workQueue中的任务。
“工具人”Worker
实际上ThreadPoolExecutor维护的工作线程就是Worker对象,我们来看Worker类的原码:
Worker继承自AbstractQueuedSynchronizer,并实现了Runnable接口。
我们重点关注构造方法,尤其是this.thread = getThreadFactory().newThread(this),通过线程工厂创建线程,传入的Runnable接口是谁?
是Worker对象本身,也就是说如果有worker.getThread().start(),此时会执行Worker.run方法。
Tips:
-
AbstractQueuedSynchronizer就是大名鼎鼎的AQS,Worker借助AQS实现非重入独占锁,不过这部分不是今天的重点; -
Woker对象与自身的成员变量thread的关系可谓是水乳交融,好好梳理下,否则会很混乱。
runWorker方法
runWorker方法传入的是Worker对象本身,来看方法实现:
大家可能会对注释1的部分比较迷惑,这个Thread wt = Thread.currentThread()是什么鬼?别急,我带你从头梳理一下。
以使用线程池中的代码为例,假设是首次执行,我们看主线程做了什么:

刚才也说了,Worker对象的线程在启动后执行worker.run,也即是在runWorker方法中Thread.currentThread()是Worker对象的线程,并非主线程。
再来看注释2的部分,第一次进入循环时,执行的task是Runnable task = w.firstTask,即初次判断task != null,第二次进入循环时,task是通过task = getTask()获取的。
线程池中,除了当前Worker正在执行的任务,还有谁可以提供待执行任务?答案是队列,因此我们可以合理得猜测getTask()是获取队列中的任务。
getTask方法
注释1的部分有两种获取任务的方式:
-
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),获取队首元素,如果当前队列为空,则等待指定时间后返回null; -
workQueue.take(),获取队首元素,如果队列为空,则一直等待,直到有返回值。
线程池只会在一种情况下使用workQueue.take,即不允许核心线程超时销毁,同时线程池的工作线程数量小于核心线程数量,结合runWorker方法的源码我们可以得知,此时借助了阻塞队列的能力,保证runsWoker方法一直停留在task = getTask()上,直到getTask()返回响应的任务。
而在选择使用workQueue.poll时存在两种情况:
- 允许核心线程超时销毁,即
allowCoreThreadTimeOut == true; - 当前工作线程数大于核心线程数,即线程池已经创建足够数量的核心线程,并且队列已经饱和,开始创建非核心线程处理任务。
结合runWorker方法的源码我们可以知道,如果队列中的任务已经被消耗完毕,即getTask()返回null,则会跳出while循环,执行processWorkerExit方法。
processWorkerExit方法
processWorkerExit方法做了3件事:
- 移除“多余”的
Worker对象(允许销毁的核心线程或者非核心线程); - 尝试修改线程池状态;
- 保证在至少存活1个
Worker对象。
Tips:我跳过了tryTerminate()方法的分析,对,是故意的~~
问题解答:线程池的底层原理是如何实现的?
销毁非核心线程
设想一个场景:已经创建了足够数量的核心线程,并且队列已经饱和,仍然有任务提交时,会是怎样的执行流程?
线程池创建非核心线程处理任务,当非核心线程执行完毕后并不会立即销毁,而是和核心线程一起去处理队列中的任务。那么当所有的任务都处理完毕之后呢?
回到runWorker中,当所有任务执行完毕后再次进入循环,getTask中判断工作线程数大于和核心线程数,此时启用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),而keepAliveTime就是构建线程池时设定的线程最大空闲时间,当超过keepAliveTime后仍旧没有获得任务返回null,跳出runWorker的循环,执行processWorkerExit销毁非核心线程。
ThreadPoolExecutor拾遗
目前我们已经详细分析了线程池的执行流程,这里我会补充一些前文未涉及到的内容,因为是补充内容,所以涉及不会详细的解释源码。
预创建线程
我们在提到线程池的优点时会特别强调一句,池内保存了创建好的资源,使用时直接取出,但线程池好像依旧是首次接到任务后才会创建资源啊?
实际上,线程池提供prestartCoreThread方法,用于预创建核心线程:
如果你的程序需要做出极致的优化,可以选择预创建核心线程。
关闭和立即关闭
ThreadPoolExecutor提供了两个关闭的功能shutdown和shutdownNow:
两者的差别还是很明显的:
-
shutdown将线程池的状态改为SHUTDOWN,而shutdownNow则改为STOP; -
shutdown不返回队列中的任务,而shutdownNow返回队列中的任务,因为STOP状态不会再去执行队列的任务; -
shutdown中断空闲线程,而shutdownNow则是中断所有线程。
从实现效果上来看关闭shutdown会更“温和”一些,而立即关闭shutdownNow则更为“强烈”,仿佛语气中带着不容置疑。
拒绝策略
线程池不会无条件的接收任务,有两种情况下它会拒绝任务:
- 核心线程已满,添加到队列后,线程池不再处于RUNNING状态,此时从队列删除任务,并执行拒绝策略;
- 核心线程已满,队列已满,非核心线程已满,此时执行拒绝策略。
Java提供了RejectedExecutionHandler接口:
因此,我们可以通过实现RejectedExecutionHandler接口,完成自定义拒绝策略。另外,Java中也提供了4种默认拒绝策略:
-
AbortPolicy:直接抛出异常; -
CallerRunsPolicy:提交任务的线程执行; -
DiscardOldestPolicy:丢弃队列中最先加入的线程; -
DiscardPolicy:直接丢弃,就是啥也不干。
源码非常简单,大家自行阅读即可。
Java提供了哪些线程池
如果不想自己定义线程池,Java也贴心的提供了4种内置线程池,默认线程池通过Executors获取。
Java的命名中,s后缀通常是对应工具类,通常提供大量静态方法,例如:Collections之于Collection。所以即便属于Executor体系中的一员,但却没办法在“族谱”上出现,打工人的悲惨命运。
FixedThreadPool
固定大小线程池,核心线程数和最大线程数一样,看起来都还不错,主要的问题是通过无参构造器创建的LinkedBlockingQueue,它允许的最大长度是Integer.MAX_VALUE。
Tips:这也就是为什么《阿里巴巴Java开发手册》中不推荐的原因。
CachedThreadPool
可以说是“无限大”的线程池,接到任务就创建新线程,另外SynchronousQueue是非常特殊的队列,不存储数据,每个put操作对应一个take操作。我们来分析下实际可能发生的情况:
- 前提:大量并发涌入
- 提交第一个任务,进入队列,判断核心线程数为0,执行
addWorker(null, false),对应execute的SETP 2; - 提交第二个任务,假设第一个任务未结束,第二个任务直接提交到队列中;
- 提交第三个任务,假设第一个任务未结束,无法添加到队列中,执行
addWorker(command, false)对应execute的SETP 3。
也就是说,只要提交的够快,就会无限创建线程。
SingleThreadExecutor
只有一个线程的线程池,问题也是在于LinkedBlockingQueue,可以“无限”的接收任务。
ScheduledExecutor
用来执行定时任务,DelegatedScheduledExecutorService是对ScheduledExecutorService的包装。
在Executor体系的“族谱”中,是有体现到ScheduledExecutorService和ScheduledThreadPoolExecutor的,这部分留给大家自行分析了。
除了以上4种内置线程池外,Java还提供了内置的ForkJoinPool:
这部分是Java 8之后提供的,我们暂时按下不表,放到后期关于Fork/Join框架中详细解释。
问题解答:Java提供了哪些线程池?
合理设置线程池
通常我们在谈论合理设置线程池的时候,指的是设置线程池的corePoolSize和maximumPoolSize,合理的设置能够最大化的发挥线程池的能力。
我们先来看美团技术团队的调研结果:

无论是哪种公式,都是基于理论得出的结果,但往往理论到工程还有很长得一段路要走。
按照我的经验,合理的设置线程池可以汇总成一句话:根据理论公式预估初始设置,随后对核心业务进行压测调整线程池设置。
Java也提供了动态调整线程池的能力:
除了workQueue都能调整,本文不讨论线程池动态调整的实现。
Tips:
- 调研结果源自于《Java线程池实现原理及其在美团业务中的实践》;
- 该篇文章中也详细的讨论了动态化线程池的思路,推荐阅读。
结语
线程池的大部分内容就到这里结束了,希望大家够通过本篇文章解答绝大部分关于线程池的问题,带给大家一些帮助,如果有错误或者不同的想法,欢迎大家留言讨论。不过今天的还是遗留了两点内容:
- 阻塞队列
- Fork/Join框架
这些我会在后续的文章中和大家分享。
好了,今天就到这里了,Bye~~
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论