用Keras搞一个阅读理解机器人

标签: 用Keras搞一个阅读理解机器人 博客 51CTO博客
2023-07-28 18:24:29 291浏览
用Keras搞一个阅读理解机器人
catalogue
1. 训练集
2. 数据预处理
3. 神经网络模型设计(对话集 <-> 问题集)
4. 神经网络模型设计(问题集 <-> 回答集)
5. RNN神经网络
6. 训练
7. 效果验证
1. 训练集
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom 1
4 Daniel went back to the hallway.
5 Sandra moved to the garden.
6 Where is Daniel? hallway 4
7 John moved to the office.
8 Sandra journeyed to the bathroom.
9 Where is Daniel? hallway 4
10 Mary moved to the hallway.
11 Daniel travelled to the office.
12 Where is Daniel? office 11
13 John went back to the garden.
14 John moved to the bedroom.
15 Where is Sandra? bathroom 8
1 Sandra travelled to the office.
2 Sandra went to the bathroom.
3 Where is Sandra? bathroom 2
4 Mary went to the bedroom.
5 Daniel moved to the hallway.
6 Where is Sandra? bathroom 2
7 John went to the garden.
8 John travelled to the office.
9 Where is Sandra? bathroom 2
10 Daniel journeyed to the bedroom.
11 Daniel travelled to the hallway.
12 Where is John? office 8训练集以对话集合[2] + 问题[1] + 回答[1]的形式组成

Relevant Link:
https://s3.amazonaws.com/text-datasets/babi_tasks_1-20_v1-2.tar.gz
2. 数据预处理
0x1: 词汇表
词汇表是语料向量化的一个基础,用来将单词映射到向量空间
Here's what a "story" tuple looks like (input, query, answer):
([u'Mary', u'moved', u'to', u'the', u'bathroom', u'.', u'John', u'went', u'to', u'the', u'hallway', u'.'], [u'Where', u'is', u'Mary', u'?'], u'bathroom')0x2: 训练集编码
根据词汇表将对话 + 问题 + 答案进行数字向量化编码
Vectorizing the word sequences...
inputs_train[0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 5 16 19 18 9 1 4 21 19 18 12 1]
queries_train[0]
[ 7 13 5 2]
answers_train[0]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0.]
//训练集和测试机同时都需要编码
inputs_test[0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 4 20 19 18 12 1 5 14 19 18 9 1]
queries_test[0]
[ 7 13 4 2]
answers_test[0]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0.
0. 0. 0. 0.]0x3: size归一化Padding
根据预处理过程中找到的最长对话、最长问题、最长答案,将所有的对话/问题/答案向量全部前置Padding到一个等长的size chunk
def vectorize_stories(data, word_idx, story_maxlen, query_maxlen):
X = []
Xq = []
Y = []
for story, query, answer in data:
x = [word_idx[w] for w in story]
xq = [word_idx[w] for w in query]
y = np.zeros(len(word_idx) + 1) # let's not forget that index 0 is reserved
y[word_idx[answer]] = 1
X.append(x)
Xq.append(xq)
Y.append(y)
return (pad_sequences(X, maxlen=story_maxlen),
pad_sequences(Xq, maxlen=query_maxlen), np.array(Y))Relevant Link:
3. 神经网络模型设计(对话集 <-> 问题集)
总体来说,我们把对话集和问题集分成2路神经网络,分别迭代计算,最后合并到一个activation function中(softmax activation)。之所以将对话集和问题集分成2路然后合并为一组,是因为对话和问题之间内在是由关联性的,阅读理解题目不会平白无故提出一个和对话无关的问题
0x1: 对话集训练
1. 嵌入层 Embedding
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
Embedding层只能作为模型的第一层,我们这里把它作为模型的第一层,用来接收对话词化向量
keras.layers.embeddings.Embedding(
input_dim,
output_dim,
init='uniform',
input_length=None,
W_regularizer=None,
activity_regularizer=None,
W_constraint=None,
mask_zero=False,
weights=None,
dropout=0.0
)
1. input_dim:大或等于0的整数,字典长度,即输入数据最大下标+1
2. output_dim:大于0的整数,代表全连接嵌入的维度
3. init:初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的Theano函数。该参数仅在不传递weights参数时有意义。
4. weights:权值,为numpy array的list。该list应仅含有一个如(input_dim,output_dim)的权重矩阵
5. W_regularizer:施加在权重上的正则项,为WeightRegularizer对象
6. W_constraints:施加在权重上的约束项,为Constraints对象
7. mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常
8. input_length:当输入序列的长度固定时,该值为其长度。如果要在该层后接Flatten层,然后接Dense层,则必须指定该参数,否则Dense层的输出维度无法自动推断。
dropout:0~1的浮点数,代表要断开的嵌入比例,
输入shape
形如(samples,sequence_length)的2D张量
输出shape
形如(samples, sequence_length, output_dim)的3D张量code slice
# embed the input sequence into a sequence of vectors
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_size,
output_dim=64,
input_length=story_maxlen))2. Dropout防止过拟合
input_encoder_m.add(Dropout(0.3))0x2: 问题集训练
和对话集模型结构一样
# embed the question into a sequence of vectors
question_encoder = Sequential()
question_encoder.add(Embedding(input_dim=vocab_size,
output_dim=64,
input_length=query_maxlen))
question_encoder.add(Dropout(0.3))0x3: 合并对话集和问题集
Merge层根据给定的模式,将一个张量列表中的若干张量合并为一个单独的张量
keras.engine.topology.Merge(
layers=None,
mode='sum',
concat_axis=-1,
dot_axes=-1,
output_shape=None,
node_indices=None,
tensor_indices=None,
name=None
)
1. layers:该参数为Keras张量的列表,或Keras层对象的列表。该列表的元素数目必须大于1。
2. mode:合并模式,为预定义合并模式名的字符串或lambda函数或普通函数,如果为lambda函数或普通函数,则该函数必须接受一个张量的list作为输入,并返回一个张量。如果为字符串,则必须是下列值之一:“sum”,“mul”,“concat”,“ave”,“cos”,“dot”
3. concat_axis:整数,当mode=concat时指定需要串联的轴
4. dot_axes:整数或整数tuple,当mode=dot时,指定要消去的轴
5. output_shape:整数tuple或lambda函数/普通函数(当mode为函数时)。如果output_shape是函数时,该函数的输入值应为一一对应于输入shape的list,并返回输出张量的shape。
6. node_indices:可选,为整数list,如果有些层具有多个输出节点(node)的话,该参数可以指定需要merge的那些节点的下标。如果没有提供,该参数的默认值为全0向量,即合并输入层0号节点的输出值。
7. tensor_indices:可选,为整数list,如果有些层返回多个输出张量的话,该参数用以指定需要合并的那些张量对于Embedding层来说,输入的是2D,输出的3D,第三维度对我们价值不大,因此在Merge的时候消去
match = Sequential()
match.add(Merge([input_encoder_m, question_encoder],
mode='dot',
dot_axes=[2, 2]))0x4: 对话集和问题集激活层
match.add(Activation('softmax'))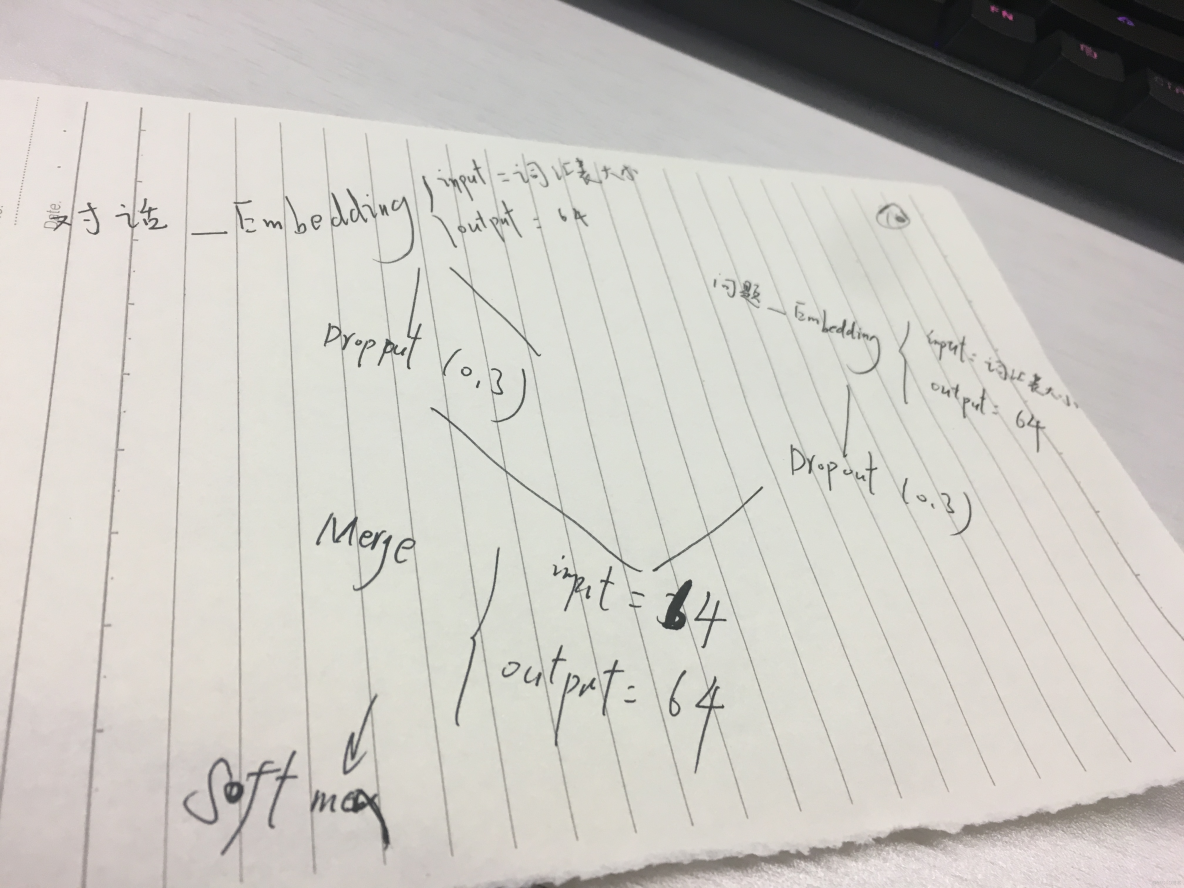
Relevant Link:
https://keras-cn.readthedocs.io/en/latest/layers/embedding_layer/
https://keras-cn.readthedocs.io/en/latest/layers/core_layer/
4. 神经网络模型设计(问题集 <-> 回答集)
同样道理,问题集和回答集之间也是有关联关系的,因此也就它们分成2路嵌套网络,最后合并到一起
# embed the input into a single vector with size = story_maxlen:
input_encoder_c = Sequential()
input_encoder_c.add(Embedding(input_dim=vocab_size,
output_dim=query_maxlen,
input_length=story_maxlen))
input_encoder_c.add(Dropout(0.3))
# output: (samples, story_maxlen, query_maxlen)
# sum the match vector with the input vector:
response = Sequential()
response.add(Merge([match, input_encoder_c], mode='sum'))
# output: (samples, story_maxlen, query_maxlen)
response.add(Permute((2, 1))) # output: (samples, query_maxlen, story_maxlen)
# concatenate the match vector with the question vector,
# and do logistic regression on top
answer = Sequential()
answer.add(Merge([response, question_encoder], mode='concat', concat_axis=-1))
5. RNN神经网络
有很多算法模型适合做这种推测型的神经网络,这里选择了RNN LSTM,RNN 是包含循环的网络,允许信息的持久化。传统的BP在面对层数较多时,能反馈到之前层的能力就会很弱了,但是RNN它能够较好地利用之前的历史训练数据,相当于一个长期记忆的能力
keras.layers.recurrent.LSTM(
output_dim,
init='glorot_uniform',
inner_init='orthogonal',
forget_bias_init='one',
activation='tanh',
inner_activation='hard_sigmoid',
W_regularizer=None,
U_regularizer=None,
b_regularizer=None,
dropout_W=0.0,
dropout_U=0.0
)
1. output_dim:内部投影和输出的维度
2. init:初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的Theano函数。
3. inner_init:内部单元的初始化方法
4. forget_bias_init:遗忘门偏置的初始化函数.建议初始化为全1元素
5. activation:激活函数,为预定义的激活函数名
6. inner_activation:内部单元激活函数
7. W_regularizer:施加在权重上的正则项,为WeightRegularizer对象
8. U_regularizer:施加在递归权重上的正则项,为WeightRegularizer对象
9. b_regularizer:施加在偏置向量上的正则项,为WeightRegularizer对象
10. dropout_W:0~1之间的浮点数,控制输入单元到输入门的连接断开比例
11. dropout_U:0~1之间的浮点数,控制输入单元到递归连接的断开比例code slice
# the original paper uses a matrix multiplication for this reduction step.
# we choose to use a RNN instead.
answer.add(LSTM(32))
# one regularization layer -- more would probably be needed.
answer.add(Dropout(0.3))
answer.add(Dense(vocab_size))
# we output a probability distribution over the vocabulary
answer.add(Activation('softmax'))Relevant Link:
http://www.jianshu.com/p/9dc9f41f0b29
https://keras-cn.readthedocs.io/en/latest/layers/recurrent_layer/
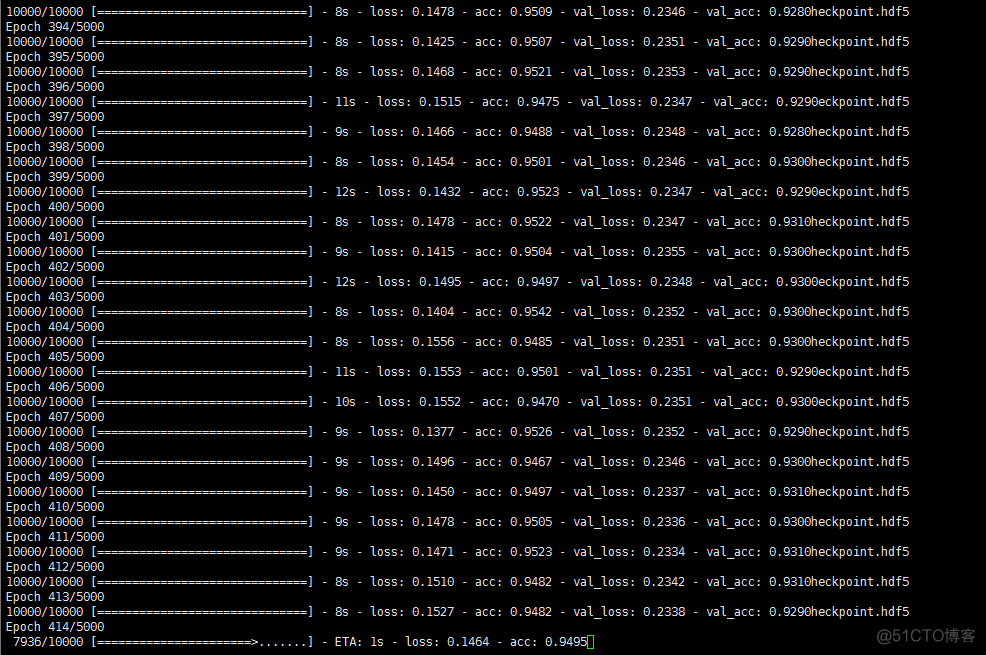
6. 训练
fit(
self,
x,
y,
batch_size=32,
nb_epoch=10,
verbose=1,
callbacks=[],
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None
)
1. x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array。如果模型的每个输入都有名字,则可以传入一个字典,将输入名与其输入数据对应起来。
2. y:标签,numpy array。如果模型有多个输出,可以传入一个numpy array的list。如果模型的输出拥有名字,则可以传入一个字典,将输出名与其标签对应起来。
3. batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
4. nb_epoch:整数,训练的轮数,训练数据将会被遍历nb_epoch次。Keras中nb开头的变量均为"number of"的意思
5. verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
6. callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
7. validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。
8. validation_data:形式为(X,y)或(X,y,sample_weights)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
9. shuffle:布尔值,表示是否在训练过程中每个epoch前随机打乱输入样本的顺序。
10. class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)。该参数在处理非平衡的训练数据(某些类的训练样本数很少)时,可以使得损失函数对样本数不足的数据更加关注。
11. sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode='temporal'。fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
0x1: 保存模型结构、训练出来的权重、及优化器状态
keras的callback参数可以帮助我们实现在训练过程中的适当时机被调用。实现实时保存训练模型以及训练参数
keras.callbacks.ModelCheckpoint(
filepath,
monitor='val_loss',
verbose=0,
save_best_only=False,
save_weights_only=False,
mode='auto',
period=1
)
1. filename:字符串,保存模型的路径
2. monitor:需要监视的值
3. verbose:信息展示模式,0或1
4. save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
5. mode:‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。
6. save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
7. period:CheckPoint之间的间隔的epoch数0x2: 当监测值不再改善时中止训练
keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=0,
verbose=0,
mode='auto'
)
1. monitor:需要监视的量
2. patience:当early stop被激活(如发现loss相比上一个epoch训练没有下降),则经过patience个epoch后停止训练。
3. verbose:信息展示模式
4. mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值停止下降则中止训练。在max模式下,当检测值不再上升则停止训练。0x3:学习率动态调整
keras.callbacks.LearningRateScheduler(schedule)
schedule:函数,该函数以epoch号为参数(从0算起的整数),返回一个新学习率(浮点数)也可以让keras自动调整学习率
keras.callbacks.ReduceLROnPlateau(
monitor='val_loss',
factor=0.1,
patience=10,
verbose=0,
mode='auto',
epsilon=0.0001,
cooldown=0,
min_lr=0
)
1. monitor:被监测的量
2. factor:每次减少学习率的因子,学习率将以lr = lr*factor的形式被减少
3. patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
4. mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值触发学习率减少。在max模式下,当检测值不再上升则触发学习率减少。
5. epsilon:阈值,用来确定是否进入检测值的“平原区”
6. cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
7. min_lr:学习率的下限当学习停滞时,减少2倍或10倍的学习率常常能获得较好的效果
0x4: code
'''Trains a memory network on the bAbI dataset.
References:
- Jason Weston, Antoine Bordes, Sumit Chopra, Tomas Mikolov, Alexander M. Rush,
"Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks",
http://arxiv.org/abs/1502.05698
- Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus,
"End-To-End Memory Networks",
http://arxiv.org/abs/1503.08895
Reaches 98.6% accuracy on task 'single_supporting_fact_10k' after 120 epochs.
Time per epoch: 3s on CPU (core i7).
'''
from __future__ import print_function
from keras.models import Sequential
from keras.layers.embeddings import Embedding
from keras.layers import Activation, Dense, Merge, Permute, Dropout
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from functools import reduce
import tarfile
import numpy as np
import re
import os
from keras.callbacks import ModelCheckpoint
from keras.callbacks import ReduceLROnPlateau
def tokenize(sent):
'''Return the tokens of a sentence including punctuation.
>>> tokenize('Bob dropped the apple. Where is the apple?')
['Bob', 'dropped', 'the', 'apple', '.', 'Where', 'is', 'the', 'apple', '?']
'''
return [x.strip() for x in re.split('(\W+)?', sent) if x.strip()]
def parse_stories(lines, only_supporting=False):
'''Parse stories provided in the bAbi tasks format
If only_supporting is true, only the sentences that support the answer are kept.
'''
data = []
story = []
for line in lines:
line = line.decode('utf-8').strip()
nid, line = line.split(' ', 1)
nid = int(nid)
if nid == 1:
story = []
if '\t' in line:
q, a, supporting = line.split('\t')
q = tokenize(q)
substory = None
if only_supporting:
# Only select the related substory
supporting = map(int, supporting.split())
substory = [story[i - 1] for i in supporting]
else:
# Provide all the substories
substory = [x for x in story if x]
data.append((substory, q, a))
story.append('')
else:
sent = tokenize(line)
story.append(sent)
return data
def get_stories(f, only_supporting=False, max_length=None):
'''Given a file name, read the file, retrieve the stories, and then convert the sentences into a single story.
If max_length is supplied, any stories longer than max_length tokens will be discarded.
'''
data = parse_stories(f.readlines(), only_supporting=only_supporting)
flatten = lambda data: reduce(lambda x, y: x + y, data)
data = [(flatten(story), q, answer) for story, q, answer in data if not max_length or len(flatten(story)) < max_length]
return data
def vectorize_stories(data, word_idx, story_maxlen, query_maxlen):
X = []
Xq = []
Y = []
for story, query, answer in data:
x = [word_idx[w] for w in story]
xq = [word_idx[w] for w in query]
y = np.zeros(len(word_idx) + 1) # let's not forget that index 0 is reserved
y[word_idx[answer]] = 1
X.append(x)
Xq.append(xq)
Y.append(y)
return (pad_sequences(X, maxlen=story_maxlen),
pad_sequences(Xq, maxlen=query_maxlen), np.array(Y))
path = ''
try:
if not os.path.isfile("babi_tasks_1-20_v1-2.tar.gz"):
path = get_file('babi_tasks_1-20_v1-2.tar.gz', origin='https://s3.amazonaws.com/text-datasets/babi_tasks_1-20_v1-2.tar.gz')
else:
path = 'babi_tasks_1-20_v1-2.tar.gz'
except:
print('Error downloading dataset, please download it manually:\n'
'$ wget http://www.thespermwhale.com/jaseweston/babi/tasks_1-20_v1-2.tar.gz\n'
'$ mv tasks_1-20_v1-2.tar.gz ~/.keras/datasets/babi-tasks-v1-2.tar.gz')
raise
if not os.path.isfile(path):
print("babi_tasks_1-20_v1-2.tar.gz downlaod faild")
exit()
tar = tarfile.open(path)
challenges = {
# QA1 with 10,000 samples
'single_supporting_fact_10k': 'tasks_1-20_v1-2/en-10k/qa1_single-supporting-fact_{}.txt',
# QA2 with 10,000 samples
'two_supporting_facts_10k': 'tasks_1-20_v1-2/en-10k/qa2_two-supporting-facts_{}.txt',
}
challenge_type = 'single_supporting_fact_10k'
challenge = challenges[challenge_type]
print('Extracting stories for the challenge:', challenge_type)
train_stories = get_stories(tar.extractfile(challenge.format('train')))
test_stories = get_stories(tar.extractfile(challenge.format('test')))
vocab = sorted(reduce(lambda x, y: x | y, (set(story + q + [answer]) for story, q, answer in train_stories + test_stories)))
print('vocab')
print(vocab)
# Reserve 0 for masking via pad_sequences
vocab_size = len(vocab) + 1
story_maxlen = max(map(len, (x for x, _, _ in train_stories + test_stories)))
query_maxlen = max(map(len, (x for _, x, _ in train_stories + test_stories)))
print('-')
print('Vocab size:', vocab_size, 'unique words')
print('Story max length:', story_maxlen, 'words')
print('Query max length:', query_maxlen, 'words')
print('Number of training stories:', len(train_stories))
print('Number of test stories:', len(test_stories))
print('-')
print('Here\'s what a "story" tuple looks like (input, query, answer):')
print(train_stories[0])
print('-')
print('Vectorizing the word sequences...')
word_idx = dict((c, i + 1) for i, c in enumerate(vocab))
inputs_train, queries_train, answers_train = vectorize_stories(train_stories, word_idx, story_maxlen, query_maxlen)
inputs_test, queries_test, answers_test = vectorize_stories(test_stories, word_idx, story_maxlen, query_maxlen)
print('inputs_train[0]')
print(inputs_train[0])
print('queries_train[0]')
print(queries_train[0])
print('answers_train[0]')
print(answers_train[0])
print ('inputs_test[0]')
print(inputs_test[0])
print('queries_test[0]')
print(queries_test[0])
print('answers_test[0]')
print(answers_test[0])
print('-')
print('inputs: integer tensor of shape (samples, max_length)')
print('inputs_train shape:', inputs_train.shape)
print('inputs_test shape:', inputs_test.shape)
print('-')
print('queries: integer tensor of shape (samples, max_length)')
print('queries_train shape:', queries_train.shape)
print('queries_test shape:', queries_test.shape)
print('-')
print('answers: binary (1 or 0) tensor of shape (samples, vocab_size)')
print('answers_train shape:', answers_train.shape)
print('answers_test shape:', answers_test.shape)
print('-')
print('Compiling...')
######################################## story - question_encoder ########################################
# embed the input sequence into a sequence of vectors
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_size,
output_dim=64,
input_length=story_maxlen))
input_encoder_m.add(Dropout(0.3))
# output: (samples, story_maxlen, embedding_dim)
# embed the question into a sequence of vectors
question_encoder = Sequential()
question_encoder.add(Embedding(input_dim=vocab_size,
output_dim=64,
input_length=query_maxlen))
question_encoder.add(Dropout(0.3))
# output: (samples, query_maxlen, embedding_dim)
# compute a 'match' between input sequence elements (which are vectors)
# and the question vector sequence
match = Sequential()
match.add(Merge([input_encoder_m, question_encoder],
mode='dot',
dot_axes=[2, 2]))
match.add(Activation('softmax'))
# output: (samples, story_maxlen, query_maxlen)
######################################## story - question_encoder ########################################
# embed the input into a single vector with size = story_maxlen:
input_encoder_c = Sequential()
input_encoder_c.add(Embedding(input_dim=vocab_size,
output_dim=query_maxlen,
input_length=story_maxlen))
input_encoder_c.add(Dropout(0.3))
# output: (samples, story_maxlen, query_maxlen)
# sum the match vector with the input vector:
response = Sequential()
response.add(Merge([match, input_encoder_c], mode='sum'))
# output: (samples, story_maxlen, query_maxlen)
response.add(Permute((2, 1))) # output: (samples, query_maxlen, story_maxlen)
# concatenate the match vector with the question vector,
# and do logistic regression on top
answer = Sequential()
answer.add(Merge([response, question_encoder], mode='concat', concat_axis=-1))
# the original paper uses a matrix multiplication for this reduction step.
# we choose to use a RNN instead.
answer.add(LSTM(32))
# one regularization layer -- more would probably be needed.
answer.add(Dropout(0.3))
answer.add(Dense(vocab_size))
# we output a probability distribution over the vocabulary
answer.add(Activation('softmax'))
# checkpoint
checkpointer = ModelCheckpoint(filepath="./checkpoint.hdf5", verbose=1)
# learning rate adjust dynamic
lrate = ReduceLROnPlateau(min_lr=0.00001)
answer.compile(optimizer='rmsprop', loss='categorical_crossentropy',
metrics=['accuracy'])
# Note: you could use a Graph model to avoid repeat the input twice
answer.fit(
[inputs_train, queries_train, inputs_train], answers_train,
batch_size=32,
nb_epoch=5000,
validation_data=([inputs_test, queries_test, inputs_test], answers_test),
callbacks=[checkpointer, lrate]
)
Relevant Link:
https://keras-cn.readthedocs.io/en/latest/models/model/
7. 效果验证
predict的网络结构需要和train的时候保持一样,我们可以使用model.load将训练时保存的模型以及参数载入进来
0x1; 题目: target.story
1 little go back to the alibaba.
2 hann join to the jiangnan university.
3 Where is little?0x2: code
'''Trains a memory network on the bAbI dataset.
References:
- Jason Weston, Antoine Bordes, Sumit Chopra, Tomas Mikolov, Alexander M. Rush,
"Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks",
http://arxiv.org/abs/1502.05698
- Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus,
"End-To-End Memory Networks",
http://arxiv.org/abs/1503.08895
Reaches 98.6% accuracy on task 'single_supporting_fact_10k' after 120 epochs.
Time per epoch: 3s on CPU (core i7).
'''
from __future__ import print_function
from keras.models import Sequential
from keras.layers.embeddings import Embedding
from keras.layers import Activation, Dense, Merge, Permute, Dropout
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from functools import reduce
import tarfile
import numpy as np
import re
import os
from keras.callbacks import ModelCheckpoint
from keras.callbacks import ReduceLROnPlateau
from keras.models import load_model
def tokenize(sent):
'''Return the tokens of a sentence including punctuation.
>>> tokenize('Bob dropped the apple. Where is the apple?')
['Bob', 'dropped', 'the', 'apple', '.', 'Where', 'is', 'the', 'apple', '?']
'''
return [x.strip() for x in re.split('(\W+)?', sent) if x.strip()]
def parse_stories(lines, only_supporting=False):
'''Parse stories provided in the bAbi tasks format
If only_supporting is true, only the sentences that support the answer are kept.
'''
data = []
story = []
for line in lines:
line = line.decode('utf-8').strip()
nid, line = line.split(' ', 1)
nid = int(nid)
if nid == 1:
story = []
if '\t' in line:
q, a, supporting = line.split('\t')
q = tokenize(q)
substory = None
if only_supporting:
# Only select the related substory
supporting = map(int, supporting.split())
substory = [story[i - 1] for i in supporting]
else:
# Provide all the substories
substory = [x for x in story if x]
data.append((substory, q, a))
story.append('')
else:
sent = tokenize(line)
story.append(sent)
return data
def parse_stories_target(lines, only_supporting=False):
'''Parse stories provided in the bAbi tasks format
If only_supporting is true, only the sentences that support the answer are kept.
'''
data = []
story = []
for line in lines:
line = line.decode('utf-8').strip()
nid, line = line.split(' ', 1)
nid = int(nid)
if nid == 1:
story = []
print(line)
sent = tokenize(line)
story.append(sent)
substory = story[:len(story) - 1]
query = story[-1]
data.append((substory, query))
return data
def get_stories(f, only_supporting=False, max_length=None):
'''Given a file name, read the file, retrieve the stories, and then convert the sentences into a single story.
If max_length is supplied, any stories longer than max_length tokens will be discarded.
'''
data = parse_stories(f.readlines(), only_supporting=only_supporting)
flatten = lambda data: reduce(lambda x, y: x + y, data)
data = [(flatten(story), q, answer) for story, q, answer in data if not max_length or len(flatten(story)) < max_length]
return data
def get_stories_target(f, only_supporting=False, max_length=None):
'''Given a file name, read the file, retrieve the stories, and then convert the sentences into a single story.
If max_length is supplied, any stories longer than max_length tokens will be discarded.
'''
data = parse_stories_target(f.readlines(), only_supporting=only_supporting)
print('parse_stories_target')
print(data)
flatten = lambda data: reduce(lambda x, y: x + y, data)
data = [(flatten(story), q) for story, q in data if not max_length or len(flatten(story)) < max_length]
return data
def vectorize_stories(data, word_idx, story_maxlen, query_maxlen):
X = []
Xq = []
for story, query in data:
x = [word_idx[w] for w in story]
xq = [word_idx[w] for w in query]
X.append(x)
Xq.append(xq)
return (
pad_sequences(X, maxlen=story_maxlen),
pad_sequences(Xq, maxlen=query_maxlen)
)
path = 'babi_tasks_1-20_v1-2.tar.gz'
if not os.path.isfile(path):
print("babi_tasks_1-20_v1-2.tar.gz not exist")
exit()
tar = tarfile.open(path)
challenges = {
# QA1 with 10,000 samples
'single_supporting_fact_10k': 'tasks_1-20_v1-2/en-10k/qa1_single-supporting-fact_{}.txt',
# QA2 with 10,000 samples
'two_supporting_facts_10k': 'tasks_1-20_v1-2/en-10k/qa2_two-supporting-facts_{}.txt',
}
challenge_type = 'single_supporting_fact_10k'
challenge = challenges[challenge_type]
print('Extracting stories for the challenge:', challenge_type)
train_stories = get_stories(tar.extractfile(challenge.format('train')))
test_stories = get_stories(tar.extractfile(challenge.format('test')))
# get the vocab, which is same as the train
vocab = sorted(reduce(lambda x, y: x | y, (set(story + q + [answer]) for story, q, answer in train_stories + test_stories)))
print('vocab')
print(vocab)
# Reserve 0 for masking via pad_sequences
vocab_size = len(vocab) + 1
story_maxlen = max(map(len, (x for x, _, _ in train_stories + test_stories)))
query_maxlen = max(map(len, (x for _, x, _ in train_stories + test_stories)))
print('-')
print('Vocab size:', vocab_size, 'unique words')
print('Story max length:', story_maxlen, 'words')
print('Query max length:', query_maxlen, 'words')
print('Number of training stories:', len(train_stories))
print('Number of test stories:', len(test_stories))
print('-')
print('Here\'s what a "story" tuple looks like (input, query, answer):')
print(train_stories[0])
print('-')
print('Vectorizing the word sequences...')
word_idx = dict((c, i + 1) for i, c in enumerate(vocab))
# get the vec of the target story we input
with open("./target.story") as fs:
target_input = get_stories_target(fs)
target_storys, target_queries = vectorize_stories(target_input, word_idx, story_maxlen, query_maxlen)
print('target_storys[0]')
print(target_storys[0])
print('target_queries[0]')
print(target_queries[0])
print('-')
print('inputs: integer tensor of shape (samples, max_length)')
print('inputs_train shape:', target_storys.shape)
print('-')
print('queries: integer tensor of shape (samples, max_length)')
print('queries_train shape:', target_queries.shape)
print('-')
print('Compiling...')
# laod the model
answer_model = load_model('./checkpoint.hdf5')
answer_output = answer_model.predict([target_storys], batch_size=32, verbose=1)
print(answer_output)实做的时候发现几问题
1. 如果我们用于训练的语料库不够完备,就会造成我的词汇表不够完备,从而直接导致在进行词向量化的时候解析失败,从而后续的归类也无法进行了
2. 在递归下降的过程中,我们可能遇到2种情况
1) 小型的凹槽
2) 真正的谷底(可能很陡峭,是突然下降的那种)
这2种情况造成的现象都可能是在连续几个spoch中,loss不再减少或者降低很微小,这个时候我们要慎重使用learning rate自动调整(实际上是降低,例如常见的10%)策略,因为这有可能导致我们过早地收敛在一个假的小凹槽中,而无法下降都真正的最佳谷底。但是反过来将,如果遇到的是那种很深且突然下降的谷底,我们的learning rate太大可能导致我们始终无法收敛到最佳值,而一直在最佳值左右晃动Relevant Link:
Copyright (c) 2017 LittleHann All rights reserved
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论