百模大战,谁是大模型的裁判员?

标签: 百模大战,谁是大模型的裁判员?
2023-07-26 18:23:41 431浏览

作者 | 袁滚滚
责编 | 唐小引
出品 | CSDN AI 科技大本营
定义了树-邻接语法(TAG)的阿拉文德·乔西(Aravind Joshi)教授,曾提出过“如果没有基准来评估模型,就像不造望远镜的天文学家想看星星。”
截至目前,国内外已有数百种大模型出世,但无论何种大模型,在亮相阶段,无一例外地都在强调自身的参数量,以及在各个评测基准上的评分。
比如,前不久Meta刚宣布开源并支持商用的Llama2,就明确使用MMLU、TriviaQA、Natural Questions、GSM8K、HumanEval、BoolQ、HellaSwag、OpenBookQA、QuAC、Winogrande等多类数据集进行评测。OpenAI则在GPT-4的报告GPT-4 Technical Report中,详细展示了在各类型考试中的成绩,以及在MMLU、HellaSwag、ARC、WinoGrande、HumanEval、DROP等学术基准中的表现。
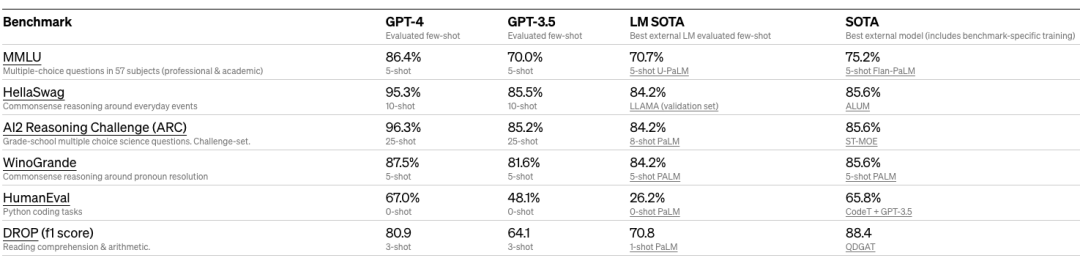
GPT-4 各类基准测试对比(来源:GPT-4 Technical Report)
因为各个模型的基座、技术路径都不尽相同,所以参数量和评测基准的评分这两类指标相对直观,这也使得模型评测基准已经成为了业内衡量模型各方面性能的工具。

大模型评测基准演进之路
在规范化的模型评测基准出现以前,模型多数使用SQuAD、Natural Questions这类问答数据集来检验模型效果,之后衍生出了多任务、系列任务的评测基准,来进行更复杂、全面的评测。
自GLUE作为最早明确、规范的大语言模型评测基准发布以来,在大语言模型评测基准的议题上,主要分为几条评测路径:
一是以GLUE为代表,通过评估模型在自然语言推断、文本蕴含、情感分析、语义相似等NLU(自然语言理解)静态任务上的表现。
二是以MMLU、AGIEval为代表,通过收集真实世界中的书籍、考试等资料,形成选择题、问答题等任务。例如MMLU向大模型提出多选问答任务,涵盖57个领域知识,包括STEM、人文社科等学科,目的是考察大模型在多样性、高级知识任务上的推理能力的表现。
三是以HELM为代表,这类基准着重场景划分,评测各种场景下的模型表现。例如HELM提出了16个场景,并结合7个指标进行细粒度测量,进一步加强了大语言模型的透明度。除了评测基准,近年还涌现了多个垂直知识领域的评测基准。
除此以外,还有进一步细分的文本任务、多语言评测基准、安全评测基准等评测路径。也有为了直观地展现模型效果,让人类参与评测,出现了Chatbot Arena这类基于Elo评分系统的工具,在国内也有SuperClue琅琊榜提供类似服务。
近期由吉林大学、微软研究院、中国科学院自动化所等机构发布的论文 A Survey on Evaluation of Large Language Models(https://arxiv.org/abs/2307.03109)中,罗列了全球主要的大模型评测基准。
 来源:A Survey on Evaluation of Large Language Models
来源:A Survey on Evaluation of Large Language Models
中文世界同样需要适应中文语言类型的基准大模型,所以近期在国内也陆续涌现了多个中文大模型评测基准,这些模型基准基本对标传统模型基准技术路径,进行了针对中文大模型评测基准的改进和优化。
不少中文大模型已经经历了多个版本的迭代,衍生出完整的测评矩阵,有些计划上线更丰富的产品,形成一站式测评平台。
CSDN收录中文大模型基准产品(部分)
| 项目名称 |
团队 |
特点 |
C-Eval |
上海交通大学 清华大学 爱丁堡大学等 |
覆盖人文,社科,理工,其他专业四个大方向,52 个学科共 13948 道题目的中文知识和推理型测试集 |
CMMLU |
MBZUAI 上海交通大学 微软亚洲研究院等 |
涵盖了从基础学科到高级专业水平的67个学科,每个学科至少有105个问题,11528个问题 |
CLUE |
CLUE团队 |
提供多种类型的评测基准模型、数据集、排行榜、Elo评分工具等 |
FlagEval |
智源 |
20+ 个主客观评测数据集,涵盖了公开数据集 HellaSwag、MMLU、C-Eval ,智源自建的主观评测数据集CCLC |
OpenCompass |
OpenMMlab |
大模型评测一站式平台,提供 50+ 个数据集约 30 万题的的模型评测方案 |
KoLA |
清华大学团队 |
基于维基百科和近90天的新闻与小说作为数据集,从知识记忆、知识理解、知识应用、知识创建四个维度,设计共119个任务 |
PandaLM |
西湖大学 北京大学等 |
PandaLM的自动化打分模型基于三位专业标注员对不同大模型的输出进行独立打分,并构建了包含 50 个领域、1000 个样本的多样化测试集 |
GAOKAO |
OpenLMLab |
收集了2010-2022年全国高考考题,其中包括1781道客观题和1030道主观题,评测分为两部分,自动化评测的客观题部分和依赖于专家打分的主观题部分,构成了最终评分 |
Xiezhi獬豸 |
复旦大学 肖仰华教授团队 |
由 249587 道多项选择题组成,涵盖 516 个不同学科和四个难度级别 |
国内大模型梳理与评测基准完整列表(持续更新)
模型基准的评分能否全面、客观地展现模型能力,排行榜是否证明了模型之间的优劣?
CSDN了解到大部分大模型团队对于评测基准较为重视,有受访者向CSDN表示评测基准给模型的调整方向提供了参考,团队可以通过模型在评测基准中的表现,对模型进行优化,同时能够了解自身与其他模型之间的差距和差异,具有一定的借鉴意义。
也有尚未进行基准评测的大模型团队,其中有受访团队提到,目前中文大模型评测基准多是MMLU路径,侧重于考验模型的知识能力,但对于想要衡量模型性能,还存在一定的局限性。同时这类基于考试、学术知识的数据集相对透明,易于获得,也会影响评分、排行榜排名的客观性。
所以,虽然模型评测基准是目前衡量模型性能的有效工具,但它们能否成为中文大模型竞赛中公正的裁判员,需要基准本身也需要向全面、客观、精准方向继续努力。根据当下火热的模型创业趋势,我们可以乐观地预见无论是中文大模型,还是中文大模型评测基准,都将在未来维持不断追赶的进步趋势与创新动力。

百模格局已现,后续如何发力?
大模型步履不停,但方向是否走对了呢?
根据CSDN的最新统计,国内已经涌现出的各类通用大模型过百家。群雄逐鹿中,通用大模型继续堆资源,重点聚焦在参数量和推理能力的提升上,各个模型团队也在发力探索适合的技术演进路径。
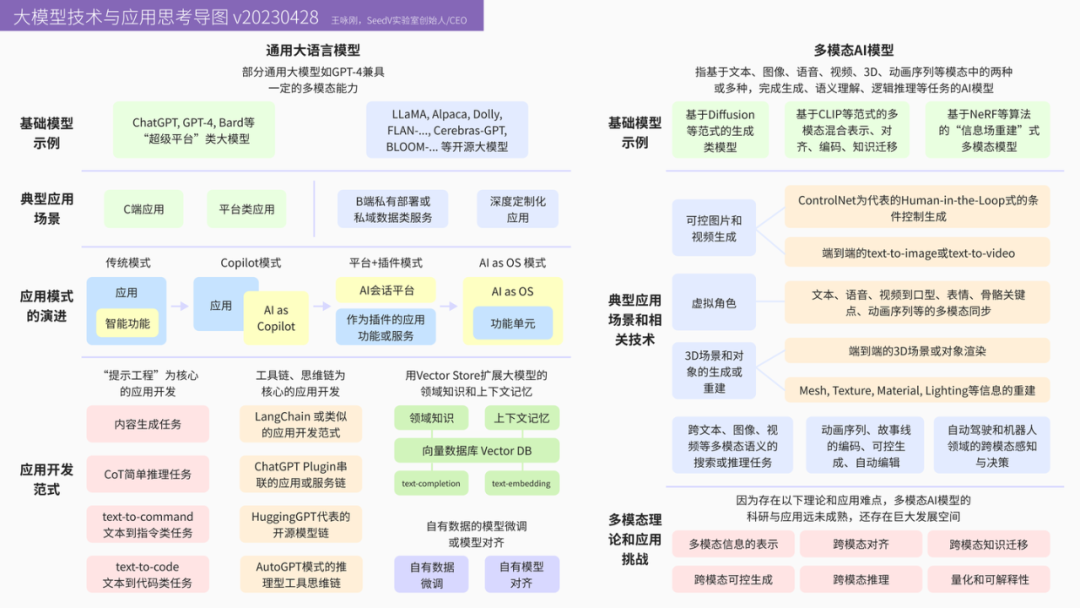
大模型技术与应用思考导图(v20230428)
王咏刚 SeedV实验室创始人/CEO
智谱AI研发的ChatGLM、王小川领衔所做的Baichuan前后宣布开源大模型,并免费商用,期待链接更多场景挖掘价值,快速搭建生态。行业模型则在尽可能探索商业化场景,百姓AI创始人王建硕在播客节目中表示,他们经过调研后明确了会务服务的测试场景。
贾扬清曾在播客节目中提及模型的保鲜期(shelf life)概念,他认为从2012年AlexNet发布至今,在每个性能强劲的大模型发布后,只要六个月到一年左右时间,就会出现效果接近的模型。随着更多优质的通用大模型逐渐开源,模型间的技术壁垒有望进一步消除。
也有行业专家认为,虽然近期大模型的热情极为高涨,但大模型及其应用的发展,取决于企业对模型部署成本与实际产生价值的衡量。
我们常说新技术总是在短期被高估,长期被低估。大模型的热度从去年延续至今,让全社会瞩目的技术创新也在不断刷屏。随着时间和技术的推进,大模型将不再是高深莫测的技术名词。
大模型的祛魅过程中,评测基准必将是重要的一环。而建立更全面、客观、准确的评测体系,形成与大模型研究之间的良性互动,也将是从业者与评测基准团队继续探索的方向。


好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论