elk学习-filebeat概念以及配置

标签: elk学习-filebeat概念以及配置 运维博客 51CTO博客
2023-04-01 18:23:42 330浏览
filebeat
概念
filebeat是一个开源的文本日志收集器,采用go语言开发,一般安装在业务服务器上作为代理来检测日志目录或者特定的日志文件,并把他们发送到logstash,es,redis或者kafka等。可以在官方地址https://www.elastic.co/downloads/beats下载各个版本的filebeat.
本次学习使用的是6.3版本。
架构与原理
filebeat的特点是性能稳定,配置简单,占用系统资源少。
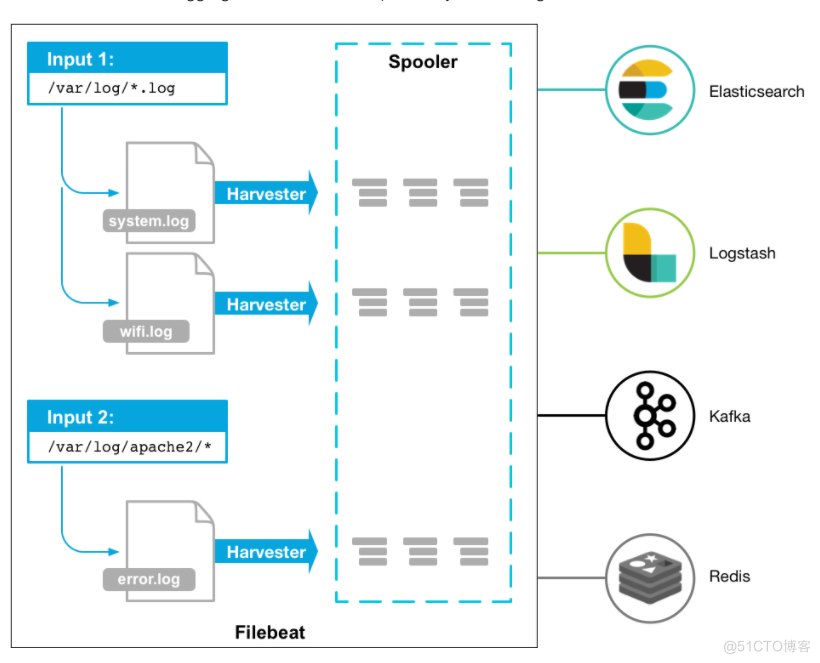
组件:
- prospector 探测器
- harvester 收集器
harvester负责单个文件的内容搜集,在运行的过程中,每个harvester会对一个文件进行逐行进行内容读取,并且把读写到的内容发送到配置的output中。当harvester运行过程中,文件都处于打开状态,如果在搜集的过程中,删除了这个文件或者对文件进行了重命名,filebeat以然继续会对这个文件进行读取,此时会一直占用文件对应的磁盘空间。直到harvester关闭。
prospector负责管理harvester,它会找到所有需要进行读取的数据源,然后交给harvester进行内容收集,如果input type是log类型,prospector会将去配置路径下查找所有能匹配的文件,然后为每一个文件创建一个harvester。
filebeat的工作流程为当开启程序的时候,它会启动一个或者多个探测器(prospector)去检测指定的日志目录或者文件,对于探测器找出每一个日志文件,filebeate会启动收集进程,每一个收集进程读取一个日志文件的内容,然后将这些日志数据发送到后台处理程序(spooler),后台处理程序会集合这些事件,最后发送集合的数据到output指定的目的地。
关于filebeat详细原理介绍,请参考官网文档
https://www.elastic.co/guide/en/beats/filebeat/6.3/how-filebeat-works.html
安装与配置
# deb
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-amd64.deb
sudo dpkg -i filebeat-6.3.2-amd64.deb
# rpm
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.3.2-x86_64.rpm
sudo rpm -vi filebeat-6.3.2-x86_64.rpm安装在deepin 20上,采用deb安装,配置文件路径为/etc/filebeat/filebeat.yml。filebeat的配置文件非常简单,以下是常用配置项
配置文件说明
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages
- /var/log/secure
fields:
log_topic: osmessages
name: "172.16.213.157"
output.kafka:
enabled: true
hosts: ["172.16.213.51:9092", "172.16.213.75:9092", "172.16.213.109:9092"]
version: "0.10"
topic: '%{[fields][log_topic]}'
partition.round_robin:
reachable_only: true
worker: 2
required_acks: 1
compression: gzip
max_message_bytes: 10000000
logging.level: info配置项说明
- filebeat.inputs: 定义数据原型
- type 指定输入类型,一般是log类型,即日志,默认值,还可以指定为stdin,即标准输入
- enabled:true 启动手工配置filebeat,e而非模块方式配置 6.3 版本以后通过模块方式快速配置filebeat,也可以手工配置,默认是模块方式配置
- paths,用于指定要监控的日志文件,可以指定一个完整路径文件,也可以是一个模糊匹配格式。例如
- /data/nginx/logs/nginx_*.log
- /var/log/*log - name: 设置filebeat收集的日志中对应的主机名字,如果配置为空,则使用该服务器的主机名
- output.kafka 支持多种输出,支持向kafak,logstash,elasticsearch输出数据
- host: 指定输出数据到kafka集群上,地址为kafka集群ip加端口号
- topic : 指定要发送数据给kafka集群的哪个topic上,若指定topic不存在,则会自动创建topic。6.x版本之前是通过%{{type}}来自动获取document_type配置项的值。6.X后是通过%{[fieds][log_topic]或者{[fileds.log_topic]}来获取日志分类的。
- logging.level 定义日志输出级别,有critical,error,warning,info,debug五种
6.版本之后,可以deb.rpm安装的filebeat可以直接启动配置模块
filebeat modules enable apache2 mysql #启动模块
filebeat modules list #检查配置的模块
filebeat -e -M "nginx.access.var.paths=[/var/log/nginx/access.log*]" #命令行参数启动配置生产上配置举例
日志输出到kalfka
filebeat.inputs:
- type: log
paths:
- "/data/logs/courseware-server/app.log.0"
- "/data/logs/courseware-server/app.log.1"
- "/data/logs/courseware-server/app.log.2"
- "/data/logs/courseware-server/app.log.3"
tags: ["h5-courseware"]
- type: log
paths:
- "/data/logs/nginx/https_coursewaremgmt.log"
tags: ["nginx-h5-coursewaremgmt"]
- type: log
paths:
- "/data/logs/nginx/https_icoursewaremgmt.log"
tags: ["nginx-h5-icourseware"]
output.kafka:
version: 0.10.2
hosts: ["172.26.5.83:9092"]
topic: 'nginx-h5'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: none
max_message_bytes: 1000000
日志输出到es
filebeat.inputs:
#################nginx#############
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
json.keys_under_root: true
json.overwrite_keys: true
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
tags: ["error"]
#################tomcat#############
- type: log
enabled: true
paths:
- /var/log/tomcat/localhost_access_log.*.txt
json.keys_under_root: true
json.overwrite_keys: true
tags: ["tomcat"]
#################es#############
- type: log
enabled: true
paths:
- /var/log/elasticsearch/elasticsearch.log
tags: ["es"]
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
#################output#############
setup.kibana:
host: "10.0.0.51:5601"
output.elasticsearch:
hosts: ["10.0.0.51:9200"]
#index: "nginx-%{[beat.version]}-%{+yyyy.MM}"
indices:
- index: "nginx-access-%{[beat.version]}-%{+yyyy.MM}"
when.contains:
tags: "access"
- index: "nginx-error-%{[beat.version]}-%{+yyyy.MM}"
when.contains:
tags: "error"
- index: "tomcat-access-%{[beat.version]}-%{+yyyy.MM}"
when.contains:
tags: "tomcat"
- index: "es-java-%{[beat.version]}-%{+yyyy.MM}"
when.contains:
tags: "es"
#es模板设置
setup.template.name: "nginx"
setup.template.pattern: "nginx-*"
setup.template.enabled: false
setup.template.overwrite: truefilebeate输出格式解读
以操作系统/var/log/secure文件日志格式举例,选取一个ssh登录失败的日志,内容如下
Aug 16 18:25:08 localhost sshd[13053]: Failed password for root from 172.16.213.37 port 49560 ssh2filebeate接收到/var/log/secure日志后,会按照之前的配置发送到kafka集群,输出的日志内容如下:
{"@timestamp":"2018-08-16T11:27:48.755Z",
"@metadata":{"beat":"filebeat","type":"doc","version":"6.3.2","topic":"osmessages"},
"beat":{"name":"filebeatserver","hostname":"filebeatserver","version":"6.3.2"},
"host":{"name":"filebeatserver"},
"source":"/var/log/secure",
"offset":11326,
"message":"Aug 16 18:25:08 localhost sshd[13053]: Failed password for root from 172.16.213.37 port 49560 ssh2",
"prospector":{"type":"log"},
"input":{"type":"log"},
"fields":{"log_topic":"osmessages"}
}以上的字段,含义如下:
- timestamp :时间戳字段,表示读取到改行内容的时间
- metadata 元数据字段,跟logstash进行交互使用
- beat beate属性信息,包括beat所在的主机名,beat版本等信息
- host 主机名字段,输出主机名,如果没有主机名,输出主机对应的ip
- source 表示监控的日志文件全路径
- offset 表示该行日志的偏移量
- message 表示正真的日志内容
- prospector filebeat对应的消息类型
- input 日志输入类型
- fileds topic对应的消息字段或者自定义增加的字段
过滤字段
通过filebeatjie接收到的内容,默认增加了不少字段,但是有些字段没有用处,可以对字段进行过滤,在filebeat配置文件中添加如下配置,即可删除不需要字段
processors:
- drop_fileds:
fields: ["beat", "input", "source", "offset"]以上代表删除beat,input,source,offset字段,其中timestamp和metadata字段不能删除。
支持正则和条件过滤
#过滤含有DBG开头的字段
processors:
- drop_event:
when:
regexp:
message: "^DBG:"
#过滤日志源为test的信息
processors:
- drop_event:
when:
contains:
source: "test"
关于filebeat的其他使用,详细见官方文档
https://www.elastic.co/guide/en/beats/filebeat/6.3/command-line-options.html
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论
您可能感兴趣的博客
