格局打开,Meta 发布免费商业应用的开源 AI 模型 Llama 2,网友:微软又赢麻了!...

标签: 格局打开,Meta 发布免费商业应用的开源 AI 模型 Llama 2,网友:微软又赢麻了!...
2023-07-20 18:23:32 378浏览

整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
昔日的竞争对手,今日的合作盟友;
忽如一夜春风来,开源大模型迎来新局面;
今天是 OSS AI 胜利的一天;
随着 Meta 最新发布一个新的开源 AI 模型——Llama 2,网上盛赞的声音不绝于耳,甚至图灵奖得主、卷积网络之父、Meta 首席人工智能科学家 Yann LeCun 更是直言,「这将改变 LLM 市场的格局」。

而 Llama 2 之所以能引起这么大的反响,不仅是因为它是开源的,更主要的原因便是它可以被免费地用于研究和商业用途。与此同时,Meta 还与微软强强联手,旨在驱动 OpenAI 的 ChatGPT、Bing Chat 和其他现代聊天机器人等应用程序。
在 Meta 看来,「开放的方法是当今人工智能模型开发的正确方法,特别是在技术快速发展的生成领域。通过公开提供人工智能模型,它们可以使每个人受益。为企业、初创企业、企业家和研究人员提供其开发的工具,这些工具的开发规模是他们自己难以构建的,并以他们可能无法获得的计算能力为后盾,将为他们以令人兴奋的方式进行实验。」
仅是这一点,便是当前很多专注于大模型开发的企业无法做到的,也如网友评价的那番,格局一下被打开。

Llama 2 的前身
今日发布的 Llama 2 是 Llama(大羊驼)的后续版本。
今年 2 月,Meta 首次公开发布 LLaMA,作为具有非商业许可证的开源版本。这是一种先进的基础大型语言模型,旨在帮助研究人员推进 AI 这一子领域的工作。更小、性能更高的模型(例如 LLaMA)使研究界中无法访问大量基础设施的其他人能够研究这些模型,从而进一步实现这一重要且快速变化的领域的访问民主化。
彼时,Meta 提供多种尺寸的 LLaMA(7B、13B、33B 和 65B 参数)。仅从功能上来看,Llama 可以根据提示生成文本和代码,与其他类似聊天机器人的系统相当。
然而,当时由于担心被滥用,Meta 决定限制对模型的访问,所以也只是对具有一定资格的研究者开放,还需要写申请表格等。
不过,令人没想到的是,不久之后便有人将 LLaMA 的权重(包括经过训练的神经网络的参数值文件)泄露到了 torrent 网站,使得并没有完全开放的 LLaMA 大模型短时间内在 AI 社区大规模扩散开。
很快,经过微调的 LLaMA 的诸多模型如雨后春笋般涌现,“羊驼”家族一时太过拥挤,如斯坦福发布了 Alpaca(羊驼)、UC 伯克利开源了 Vicuna(小羊驼)、华盛顿大学提出了 QLoRA 还开源了 Guanaco(原驼)...国内哈工大还基于中文医学知识的 LLaMA 模型指令微调出了一个“华驼”。
时下,Llama 2 的发布将这款开源大模型推向一个新的高度。相比上一代 Llama 模型,经过混合公开数据的训练,Llama 2 的性能有了显著提高。

Llama 2:从 7B 到 70B 参数不等
为此,Meta 发布了一篇长达 76 页的论文《Llama 2: Open Foundation and Fine-Tuned Chat Models》详述 Llama 2 大模型的预训练、微调、安全性等相关的工作。

论文地址:https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6/10000000_663429262362723_1696968207443577320_n.pdf?_nc_cat=101&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=5ol-jUSglG4AX_EKgWk&_nc_ht=scontent-lax3-2.xx&oh=00_AfC4pQWErthyr1jwgSScKeyjXW3wwEUnqvIh7MNeb-Et3g&oe=64BBB691
据论文显示,Llama 2 有两种版本:Llama 2 和 Llama 2-Chat,后者针对双向对话进行了微调。Llama 2 和 Llama 2-Chat 进一步细分为不同复杂程度的版本:70 亿个参数、130 亿个参数和 700 亿个参数。
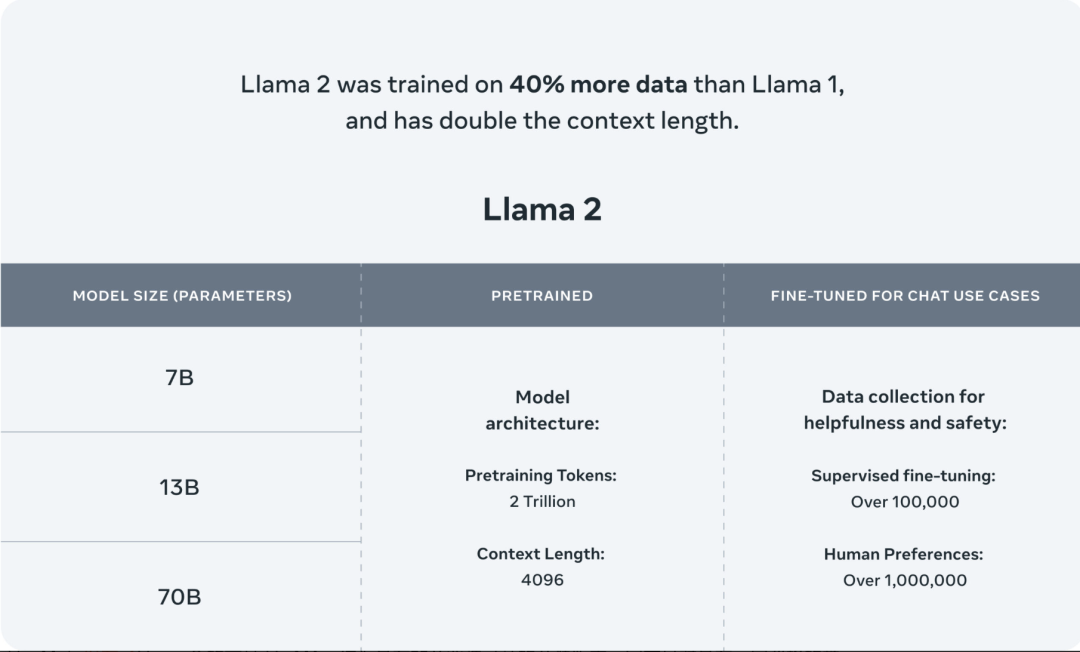
Meta 将 Llama 2 预训练语料库的规模增加了 40%,这一款模型(基本模型)接受了 2 万亿个 token 的训练,上下文窗口包含了 4096 个 token,相比上一代,提升了一倍。上下文窗口决定了模型一次可以处理的内容的长度。在硬件方面,Meta 都使用了 NVIDIA A100。
Meta 还表示,Llama 2 微调模型是为类似于 ChatGPT 的聊天应用程序开发的,已经接受了“超过 100 万条人工注释”的训练。
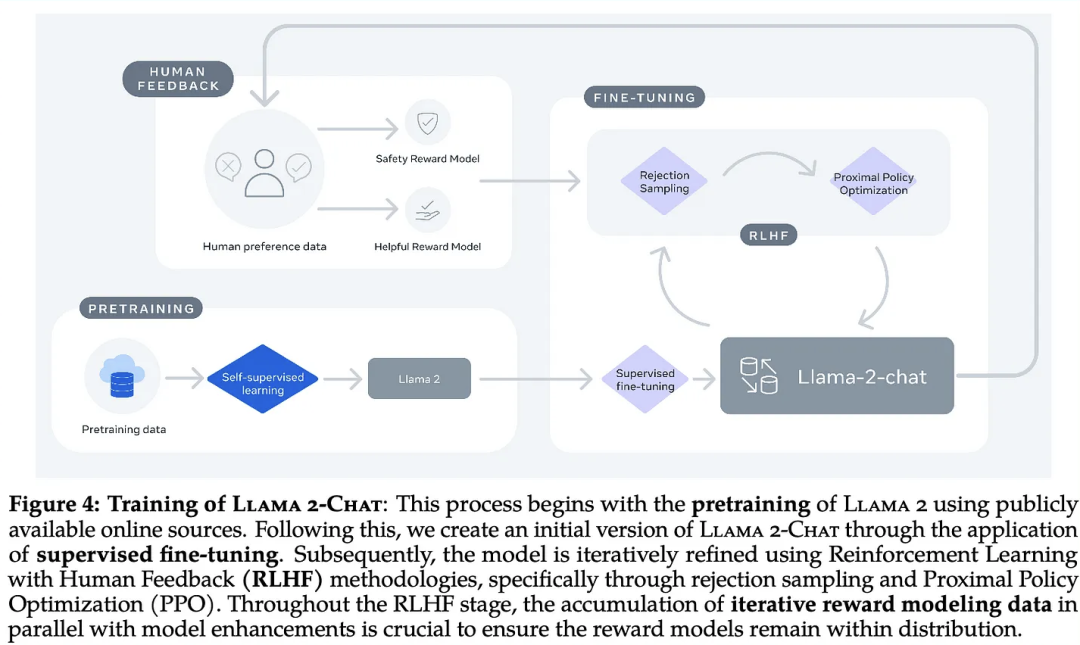
不过,Meta 在论文中并没有透露训练数据的具体来源,只是说它来自网络,其中不包括来自 Meta 的产品或服务的数据。
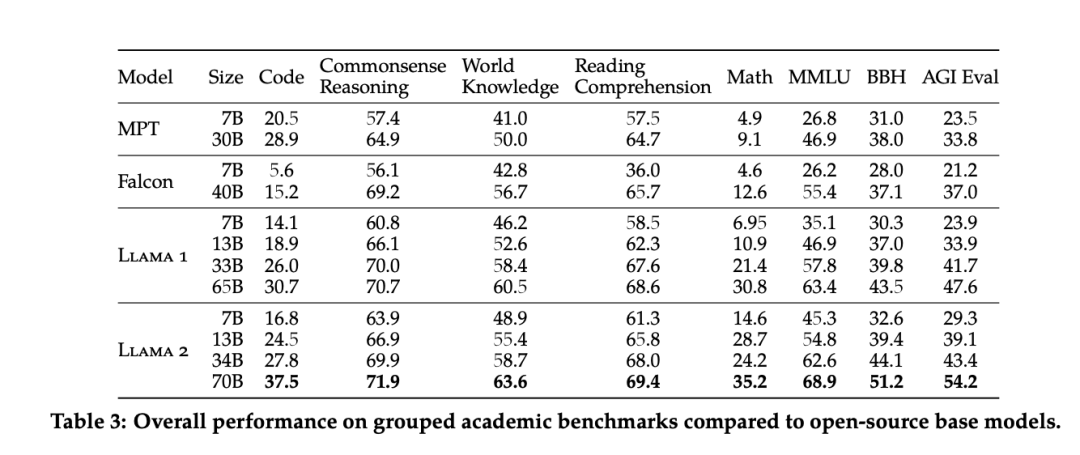
根据官方基准测试,Llama 2 在开源模型领域,一马当先。其中,Llama 2 70B 模型的性能优于所有开放源码模型。
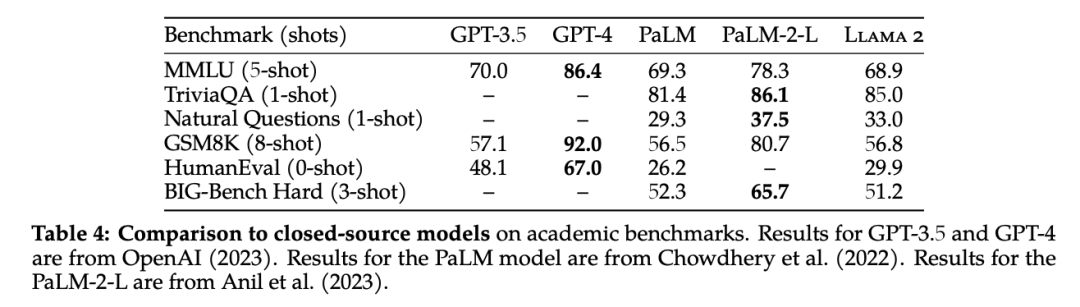
和闭源的大模型相比,Llama 2 70B 在推理任务上接近 GPT-3.5,但在编码基准上存在显著差距。同时,其在性能上还无法与 OpenAI 的 GPT-4、PaLM-2-L 相媲美,在计算机编程方面 Llama 2 明显落后于 GPT-4。
论及 Llama 2 此次真正的优势,Nvidia 高级 AI 科学家 Jim Fan 高度评价道:
Llama-2 的训练费用可能超过 2000 万美元。Meta 通过发布具有商业友好许可的模型,为社区提供了令人难以置信的服务。由于许可证问题,大公司的人工智能研究人员对 Llama-1 持谨慎态度,但现在我认为他们中的很多人都会加入进来,贡献自己的力量。
Meta 的团队对 4K 提示进行了人类研究,以评估 Llama-2 是否有用。他们使用 "胜率 "作为比较模型的指标,其精神与 Vicuna 基准类似。70B 模型与 GPT-3.5-0301 大致持平,表现明显强于 Falcon、MPT 和 Vicuna。
与学术基准相比,我更相信这些真实的人类评级。
Llama-2 还没有达到 GPT-3.5 的水平,主要是因为它的编码能力较弱。在 "HumanEval"(标准编码基准)上,它还不如 StarCoder 或其他许多专门为编码而设计的模型。尽管如此,我毫不怀疑 Llama-2 将因其开放的权重而得到显著改善。
Meta 团队在人工智能安全问题上不遗余力。事实上,这篇论文几乎有一半的篇幅都在谈论安全、红线和评估。我们要为这种负责任的努力鼓掌!
在之前的研究中,帮助性和安全性之间存在着棘手的权衡问题。Meta 通过训练两个独立的 reward 模型来缓解这一问题。这些模型还没有开源,但对社区来说非常有价值。
我认为 Llama-2 将极大地推动多模态人工智能和机器人研究。这些领域需要的不仅仅是黑盒子访问 API。
到目前为止,我们必须将复杂的感官信息(视频、音频、三维感知)转换为文本描述,然后再输入到 LLM,这样做既笨拙又会导致大量信息丢失。将感官模块直接嫁接到强大的 LLM 上会更有效。
Llama 2 的论文本身就是一部杰作。GPT-4 的技术详解论文只分享了很少的信息,而 Llama-2 则不同,它详细介绍了整个细节,包括模型细节、训练阶段、硬件、数据管道和注释过程。例如,论文对 RLHF 的影响进行了系统分析,并提供了漂亮的可视化效果。
引用第 5.1 节:"我们认为,LLMs 在某些任务中超越人类注释者的超强写作能力,从根本上说是由 RLHF 驱动的"。

来源:https://twitter.com/DrJimFan/status/1681372700881854465
不过,值得注意的是,Llama 2 虽然允许了商业使用,但是它在社区许可协议中还添加了一条附加商业条款:
如果在 Llama 2 版本发布之日,被许可方或被许可方的关联公司提供的产品或服务的每月活跃用户数在上一个日历月中超过 7 亿,则您必须向Meta申请许可,Meta 可以自行决定向您授予该权利,并且您无权行使本协议项下的任何权利,除非或直到 Meta 明确授予您此类权利。

这意味着一些大厂,譬如亚马逊、Google 这样的巨头想要使用 Llama 2,还存在一定限制。


Meta 与微软强强联手
当然,Meta 也并没有将所有大厂拒绝门外。在此次官方公告中,Meta 宣布了和微软的深度合作。
其中,作为 Llama 2 的首选合作伙伴微软,Meta 表示,从今天开始,Llama 2 可在 Azure AI 模型目录中使用,基于此,使用 Microsoft Azure 的开发人员能够使用 Llama 2 进行构建,并利用其云原生工具进行内容过滤和安全功能。

与此同时,Llama 2 还经过优化,可以在 Windows 上本地运行,为开发人员提供无缝的工作流程,为跨不同平台的客户带来生成式 AI 体验。Llama 2 也可通过 Amazon Web Services (AWS)、Hugging Face 和其他提供商获取。
有网友评论,微软这一波又赢了!

除了与微软合作之外,Meta 也与高通进行了合作。高通宣布,“计划从 2024 年起,在旗舰智能手机和 PC 上支持基于 Llama 2 的 AI 部署,赋能开发者使用骁龙平台的 AI 能力,推出激动人心的全新生成式 AI 应用。”

没有 100% 完美的大模型
不过,对于 Llama 2,Meta 公司也承认它并非绝对的完美,因为其测试不可能捕获所有现实世界场景,并且其基准测试可能缺乏多样性,换句话说,没有充分涵盖编码和人类推理等领域。
Meta 还承认,Llama 2 与所有生成式 AI 模型一样,在某些层面存在偏差。例如,由于训练数据的不平衡以及训练数据中存在“有毒”文本,它可能会制造“幻觉”、生成“有毒性”的内容。
针对这一点,Meta 选择和微软合作的一部分,也包括使用 Azure AI Content Safety,该服务旨在检测 AI 生成的图像和文本中的“不当”内容,以减少 Azure 上有毒的 Llama 2 输出。
同时,Meta 在论文中强调 Llama 2 用户除了遵守有关“安全开发和使用”的准则外,还必须遵守 Meta 的许可条款和可接受的使用政策,在一定程度上减少有偏差性的内容。

开源大模型的未来
最后,如果说 OpenAI 引领大模型赛道,那么 Meta 则开辟了开源大模型的新大门。
以开源的方式,汇聚更多的创新,Llama 2 的开源也为众人预测中的“未来,开源大模型会主导整个大模型的发展方向”带来更多可能性。
这也正如 Ars Technica 总结的:开源人工智能模型的到来,不仅鼓励透明度(用于制作模型的训练数据而言),而且促进经济竞争(不将技术限制于大公司)、鼓励言论自由(没有审查制度),并使人工智能的访问民主化(没有付费专区限制)。
同时,为了避免 Llama 2 开源存在的潜在争议,Meta 还同时发布了一封主题为《支持 Meta 对当今人工智能的开放方法的声明》的声明,其写道:
“我们支持对人工智能采取开放式创新方法。负责任和开放式创新为我们所有人提供了参与人工智能开发过程,为这些技术带来可见性、审查和信任。今天开放的 Llama 模型将使每个人都从这项技术中受益。”
截至目前,已有近百位 AI 专家参与签名,其中包括 Drew Houston(Dropbox 首席执行官)、Matt Bornstein(Andreessen Horowitz 合伙人)、Julien Chaumond(Hugging Face 首席技术官)、Lex Fridman(麻省理工学院研究科学家)和 Paul Graham(Y Combinator 的创始合伙人)等。
当然,也不容忽视的是,无论是开源还是闭源大模型,其都面临着复杂的法律问题,因为他们需要判别用于训练的数据池中是否存在受版权保护的资源。如何有效避免这些问题,也成为这些大模型开发公司下一阶段需要解决的事情。
目前,任何人都可以通过在 Meta 网站上填写表格(https://ai.meta.com/resources/models-and-libraries/llama-downloads/)来请求下载 Llama 2 ,想要尝鲜的小伙伴不妨一试!
更多资料详见:
论文地址:https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6/10000000_663429262362723_1696968207443577320_n.pdf?_nc_cat=101&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=5ol-jUSglG4AX_EKgWk&_nc_ht=scontent-lax3-2.xx&oh=00_AfC4pQWErthyr1jwgSScKeyjXW3wwEUnqvIh7MNeb-Et3g&oe=64BBB691
Llama 2:https://ai.meta.com/llama/
Llama 2申请地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Meta 官方公告:https://about.fb.com/news/2023/07/llama-2/
公开信:https://about.fb.com/news/2023/07/llama-2-statement-of-support/
推荐阅读:
▶微软Office AI工具定价每人每月30美元;Meta开源免费可商用大语言模型Llama 2;美团申请美团光年商标|极客头条

好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论
您可能感兴趣的博客