模型生成训练数据:免费的午餐还是一场梦?

2023-07-17 18:23:26 283浏览

【编者按】本文主要讨论使用一个语言模型生成另一个语言模型的训练数据的话题。作者认为,只要我们有一个足够好的模型来生成类似于目标分布的样本,并且有一个过滤函数来识别(和重新加权)这些样本,我们就可以从目标分布生成无限的数据。我们的限制不在于信息处理不等式,而在于我们覆盖和识别目标分布的能力。
原文链接:https://dblalock.substack.com/p/models-generating-training-data-huge
未经允许,禁止转载!
作者 | DAVIS BLALOCK 译者 | 明明如月
责编 | 夏萌
出品 | CSDN(ID:CSDNnews)
下面是两个让人费解的问题:
我们看到很多论文中提出,可以利用一个语言模型生成另一个语言模型的训练数据。
但是……根据数据处理不等式(数据处理不等式是一个信息论概念,它指出通过局部物理操作无法增加信号的信息内容),我们不应期待能够创造出不在第一个模型训练集中的新信息。
那么,我们应如何解决这两种矛盾的呢?模型生成训练数据是一顿几乎免费的午餐还是一种幻觉?

解释观察结果
为了解答这个问题,让我们首先回顾一些代表性的证据。如果你只想知道结论,可以直接跳到下一部分。
在我所喜欢的关于生成训练数据的实例中,有一种显著的例子是 Unnatural Instructions。从 LLM 中生成并对大量遵循指令的示例进行微调,可以大幅提高模型的质量(橙色点)。虽然不及人工生成的例子(蓝色),但比原始模型提高了许多(见正向斜率)。
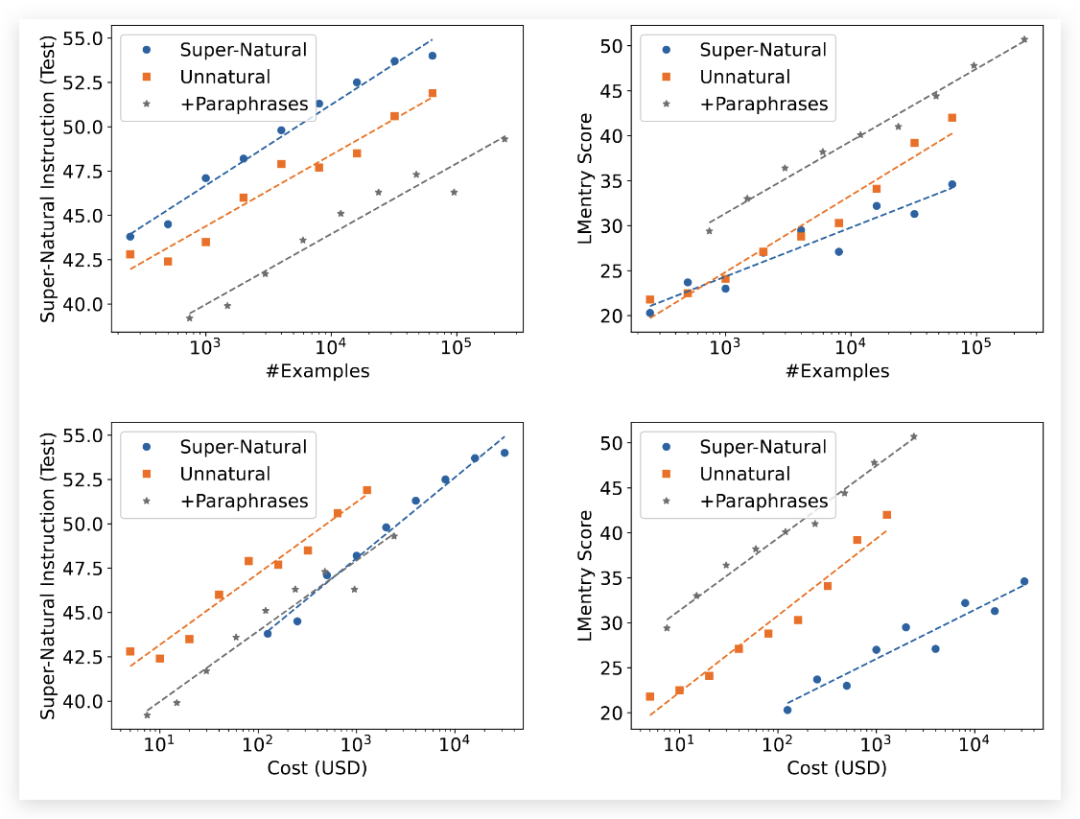
图6 :扩展实验:对比非自然指令和超自然指令。上排:在控制数据集大小的情况下,测试模型在超自然指令(左侧)和 LMentry(右侧)上的性能。下排:在控制数据获取成本的情况下,测试模型在超自然指令(左侧)和LMentry(右侧)上的性能。
此外,还有一篇论文 《语言模型可以自我学习来编写更好的程序》 同样证实了这一点。这篇论文通过迭代生成编程难题并对其进行训练,使他们的模型在编程方面更加出色。
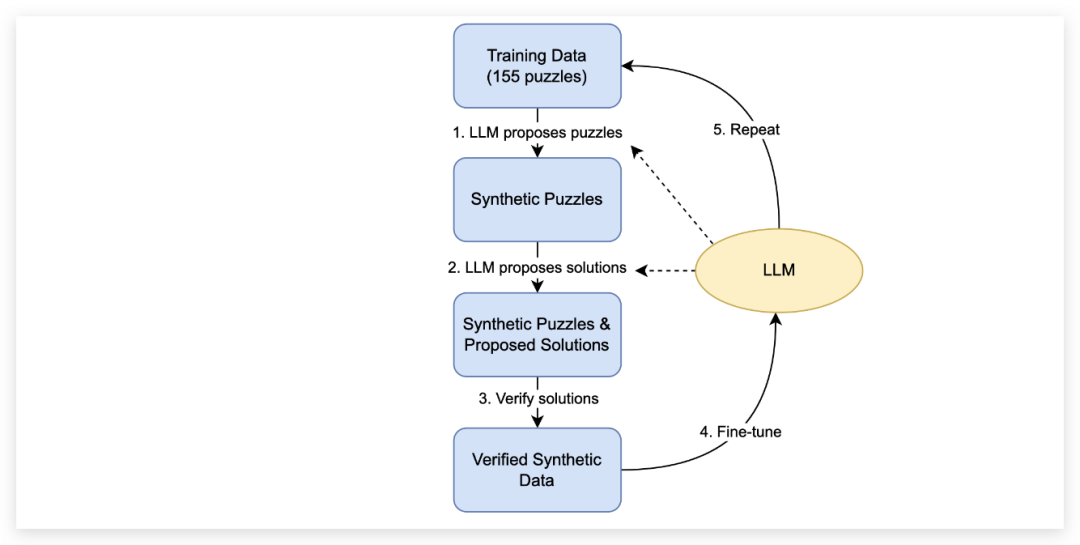
图 2 :数据生成流程,用于迭代地生成数据并对语言模型进行微调。该流程在4个不同的大型语言模型上运行:Codex、GPT-Neo 125M、1.3B和2.7B。由于 Codex 的 API 访问不允许进行微调,在第一次循环中,Codex在生成了100万个经过验证的谜题和解决方案后停在第 3步。GPT-Neo 125M、1.3B和2.7B支持微调,我们对GPT-Neo模型进行了两次循环。第一次循环从每个模型中产生了25K个独特的谜题/解决方案样本用于微调,这是一个引导步骤,极大地加快了第二次循环中使用微调模型生成数据的速度。在第二次循环中,我们从每个模型中生成了100万个独特的谜题/解决方案样本用于微调。
近期,我们看到了 《只要有教科书就够了》 使用一个小型模型和一个小而高质量的数据集(其中一部分由 GPT-3.5 生成)几乎实现了最先进的代码生成。
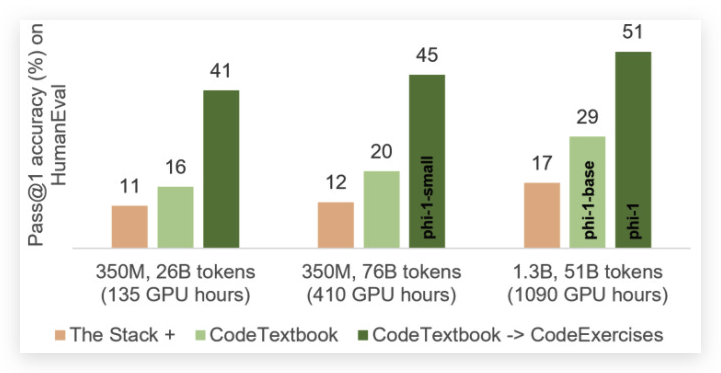
Impossible Distillation 也使用一个小型、领域特定的模型,获得了巨大的精度提升。他们用这个模型迭代生成数据,然后在这些数据上进行微调。
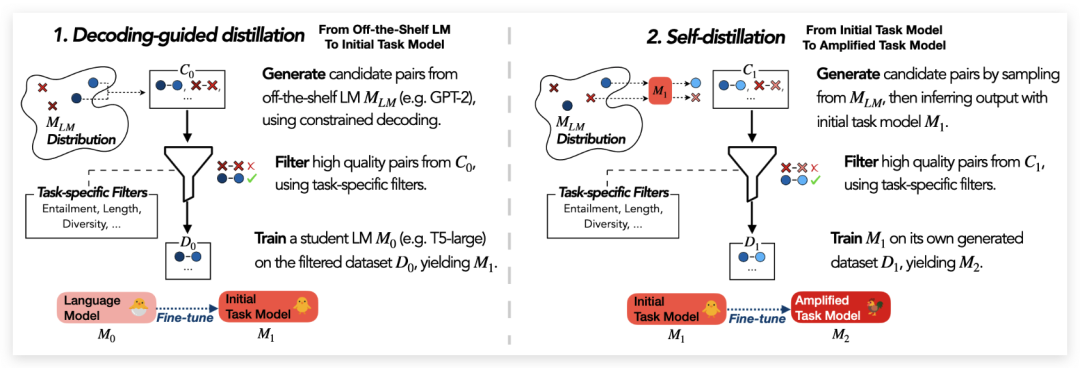
图 1:IMPOSSIBLE DISTILLATION 的概述。该方法从一个小型的现成语言模型开始,逐步生成更高质量的数据集和任务模型。这种方法在摘要和改写任务上的表现,甚至超过了200 倍的 GPT-3。
最后,Orca paper 通过提取并训练 GPT-4 的全部解释(论文中的“解释”是指对一个问题的正确答案或最佳选项进行解释。这些解释可能包括对问题的理解和逻辑推理、对答案的计算过程以及对选项的考虑等方面的解释),而不仅仅是答案,获得了巨大的精度提升。
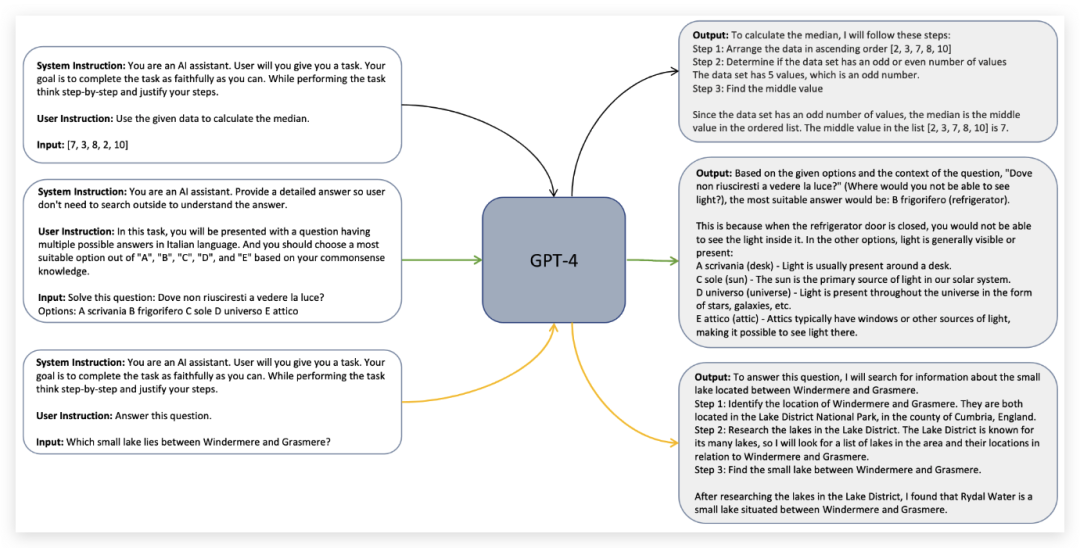
图 5:我们对 GPT-4 进行了解释性微调。在这个过程中,除了处理用户指令和输入,系统还会生成系统指令,以形成合理且有力的回应。系统指令从多样的指令集中进行抽样,这些指令包括思维链推理步骤、用通俗易懂的语言解释、提供帮助和信息等等。这种方式能生成富有深度和良好结构的回应,从而允许我们微调小型模型来模拟 GPT-4 的思考过程,这一过程是基于< {系统指令,用户指令,输入},输出> 的配对进行的。
另一方面,《模仿专有语言模型的虚假承诺》 发现,仅仅使用另一个模型的输出进行训练,虽然可以复制输出的形式,从而欺骗各种评估指标,但并不能真正提升模型的能力。
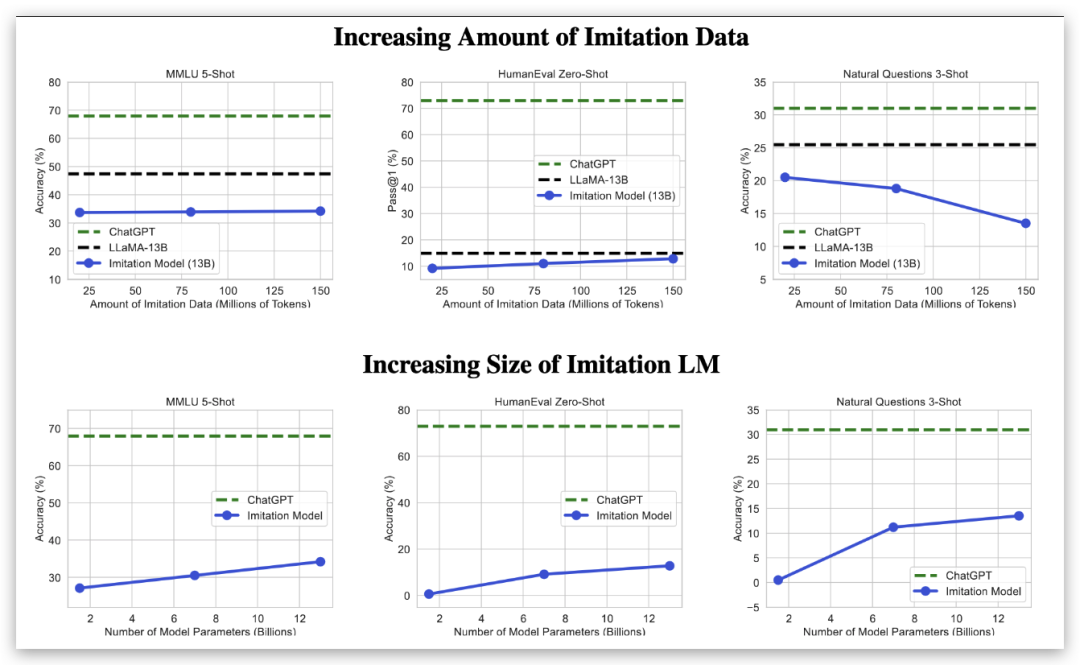
图 4:自动评估。随着我们增加模仿数据的数量,各种基准测试的改进效果很小,甚至出现了性能回归(上图)。然而,扩大基础语言模型的规模会稳定地改善结果(下图),这表明开源和闭源语言模型之间的关键差异在于原始能力的差距,而不是微调数据的使用。
同样,《递归的诅咒:在生成数据上训练会让模型忘记》 在理论和实践中都表明,如果我们以迭代方式用生成模型自己的输出进行自举,而忽略或丢弃整个数据分布中较为罕见或极端的情况。
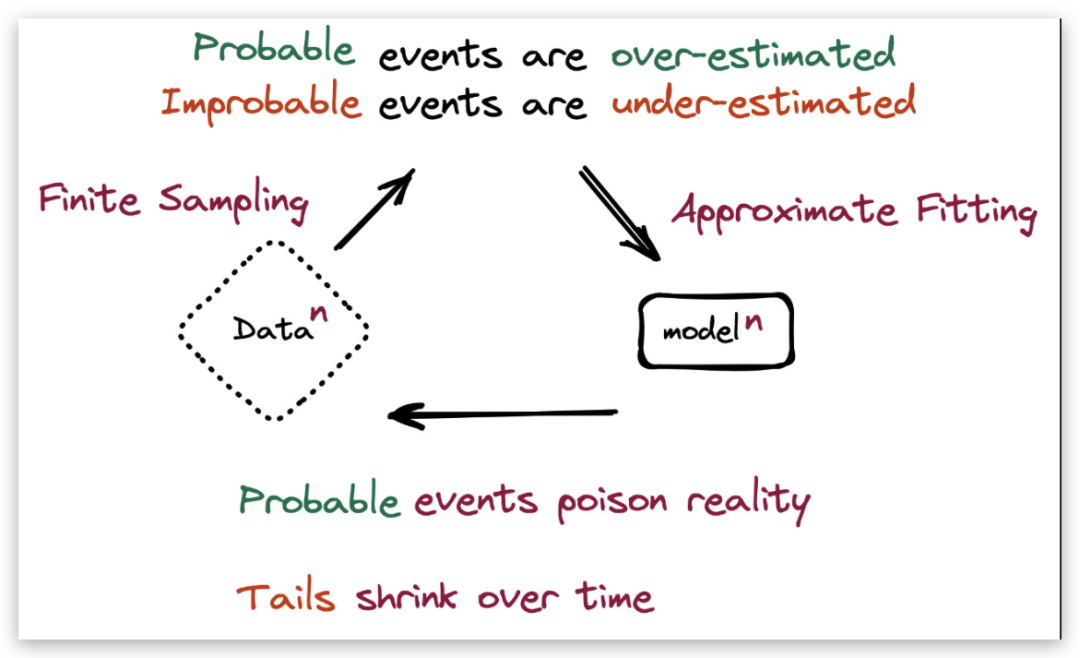
图1:模型崩溃是指一种退化的学习过程,在这个过程中,由于模型对数据分布的拟合过度,导致模型对低概率事件的预测能力下降。
在一些情况下,实证收益与数据处理不等式之间的明显矛盾很容易解决:
如果你使用像 GPT-4 这样的优秀模型为较差的模型生成示例,你可以将准确率的提升解释为知识蒸馏。
不需要创建新的信息。GPT-4 的训练集只是比你的更好。或者你的模型不论怎样都是训练不足。
如果你只看到小幅度的提升,你可以称之为“正则化”,数据增强,或者强加一个信息性先验。
例如,你可以通过将数据集增强为带有高斯噪声副本相结合,将普通的线性回归转换为岭回归。虽然没有添加新的信息,但你还是可以做得更好。
但我认为,有一种互补且更一般的解释。关键不在于生成数据的模型。关键在于过滤。下面是这个问题的思考过程。
你有一些目标分布,你希望从中生成样本,这可能类似于你训练分布的清洁版本。这些分布的重叠有几种情况。如果你的目标和生成的分布是不交叉的,那你就无法生成有效的样本。
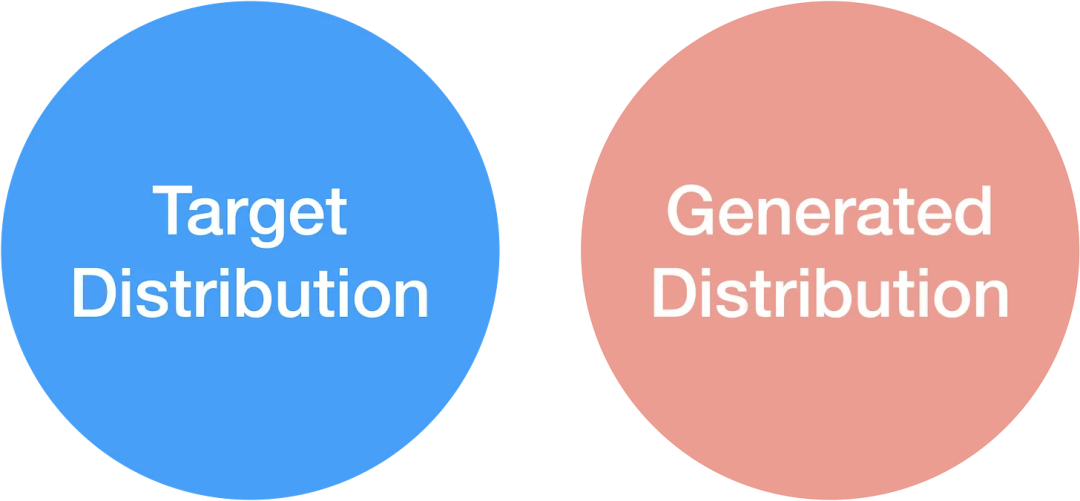
如果你不能从目标分布中生成任何样本,试图生成训练数据就不会有好结果。
如果有一些重叠,你至少可以生成一些有用的样本。但你不会得到全面覆盖,你将结束于偏差-方差的权衡。递归的诅咒中的尾部崩溃就是这样的一种情况。
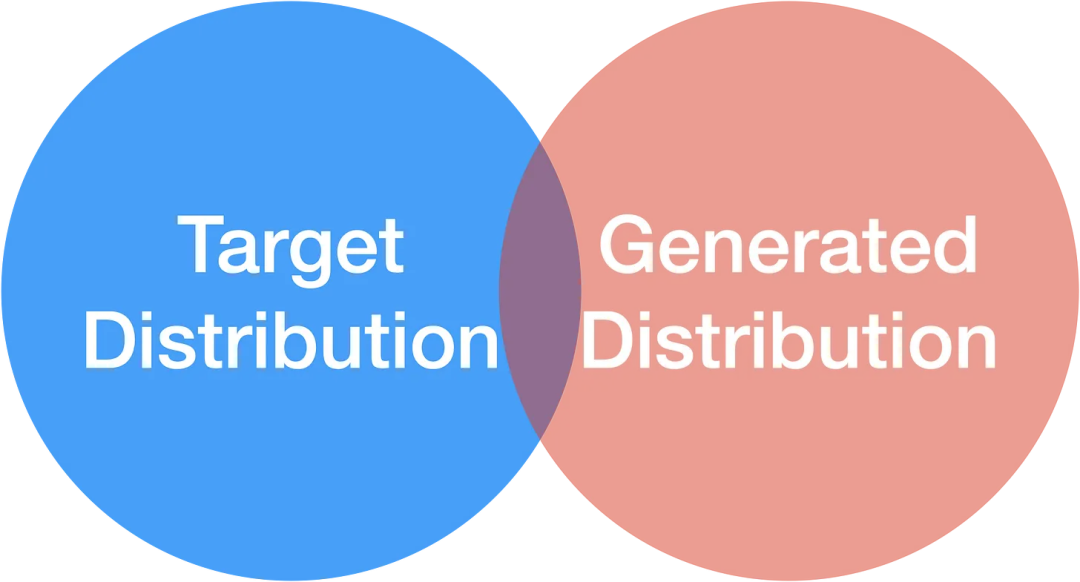
如果部分重叠,你可以生成一些有用的样本。但你会极大地偏向你的训练分布。
真正的突破是当你生成的分布完全覆盖了整个目标分布时,我们就可以用到我们统计学中最古老的朋友之一:拒绝采样。
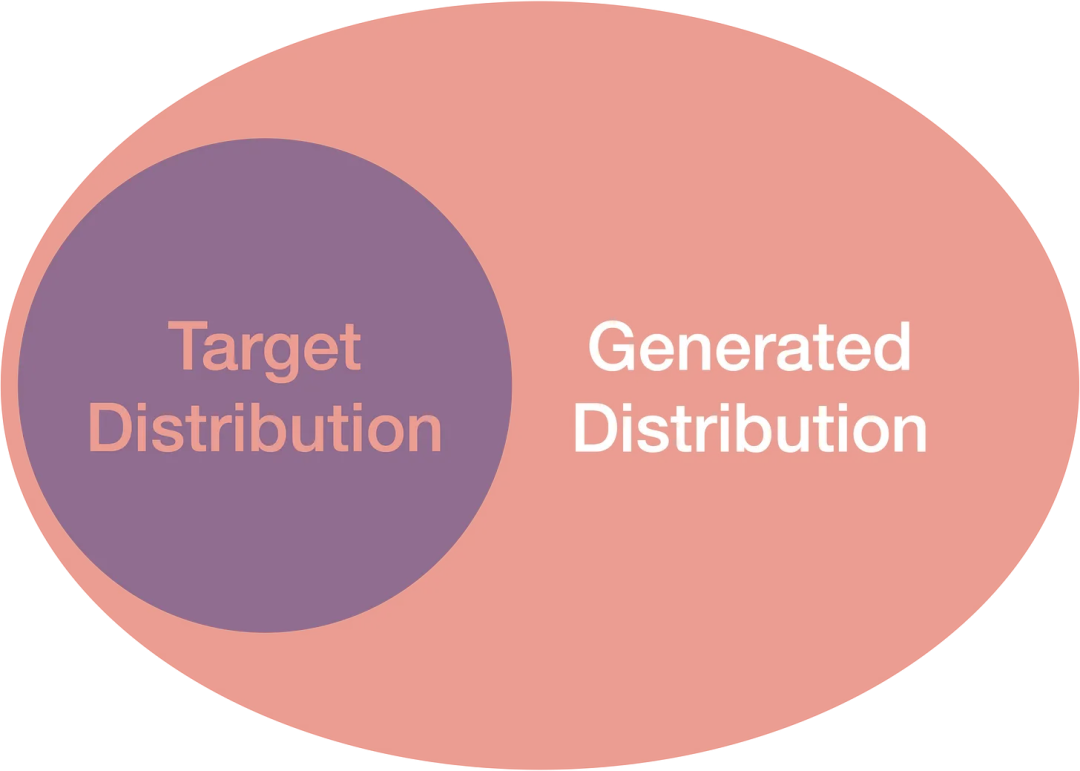
如果我们可以从我们的整个目标分布生成样本,我们就可以开始行动了。
在全覆盖的情况下,我们可以做的是使用某种过滤函数来抛弃所有不符合目标分布的生成样本。只要我们的过滤函数足够好,我们就可以使用约等于目标分布(的分布)来生成新的数据。

有良好的样本过滤可以让我们近似目标分布,只要我们的生成模型有时输出相关的样本。
要做到这一点,需要你的过滤函数能考虑到目标分布和生成分布在样本空间的每一个点的比例,并相应地进行重采样/重加权。如果你能够以某种方式对尾部进行上采样以缓解递归诅咒的问题,那么你会获得额外的加分。
除了(希望)直观上有意义外,这个观点也与我看到的结果一致。例如,在《语言模型可以自我教学以更好地编程》中,他们在只训练生成的解决方案,实际适用于生成的问题的样本时,解决了更多的编程问题。
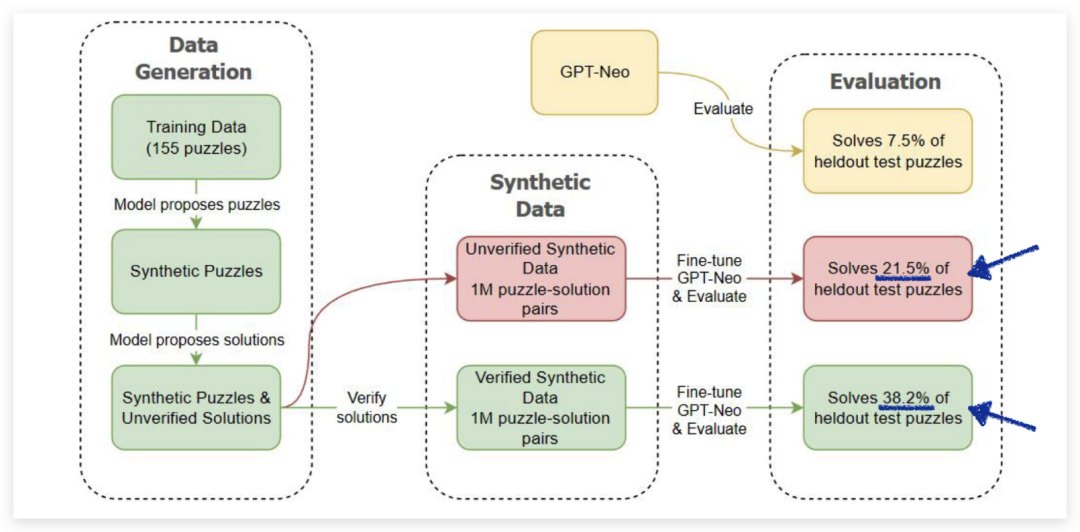
图 4:Codex 是一个基于 GPT-3 的编程语言模型,消融实验是指逐步去掉模型中某些部分或功能,观察其对性能的影响。Codex 消融实验的概述和结果如下所示。在已验证的合成谜题和解决方案上生成和微调的结果用绿色表示,而在未验证的谜题上生成和微调的结果用红色表示。GPT-Neo 基准模型的结果用黄色表示。所有性能结果均基于经过一轮微调后的 2.7B 模型。
过滤也似乎是不可能的蒸馏、Orca、和教科书就是你所需要的的关键组成部分。
这个观点并不能解释《模仿私有LLMs的虚假承诺》中的结果,但可以与它们相协调。如果表面对齐假设成立,我们大概对 GPT 生成的数据进行微调并不会有太大帮助——即使我们在生成过程中做得很好。

可测试的预测
如果我的拒绝抽样框架与实际情况相符,我们应该期待以下发现:
从太差的模型中生成训练数据是行不通的(有效性低),无论你的过滤函数多么好。这是因为一个差的模型很少生成好的样本。
保持生成分布不变, 改进或劣化你的过滤函数应该会使得在生成的数据上训练的模型变得更好或更差。
随着你的生成分布接近你的目标分布,过滤应该变得不那么重要。
基于建议分布到目标分布的比例进行重新取样 / 重新加权,会比接受所有在你的目标分布下有非零概率的样本效果更好。
我们可以从目标分布中生成无限的数据,前提是我们的生成分布覆盖了它,而且我们可以适当地重新加权或拒绝样本。

结论和启示
假设:
我们有一个足够好的模型,可以生成类似于我们目标分布的样本,以及一个能够识别(并重新加权)这些样本的过滤函数。
那我们可以从目标分布中生成大量的数据。我们并不受信息处理不等式的限制。相反,我们受到的限制是我们对目标分布的覆盖和识别能力。
这表明,在覆盖和过滤比较容易的领域,未来受训练数据限制的程度会小得多。
输入空间(有效地)具有少量可能值的领域,覆盖将会更容易。我预期许多时间序列、一些表格,甚至可能一些图像数据集都属于这个类别。
当样本具有可测试的特性时,过滤将最为容易。代码生成是这里的亮点,因为程序有形式语法,我们可以客观地评估正确性。定理证明也似乎利于过滤。自然语言则不太明确,但它至少有语法规则和评估质量的合适启发式方法。
这里的推论是,训练数据生成可能是机器学习中最紧密的正反馈环。通过更好的模型,我们不仅可以更频繁地生成目标分布中的样本,还能更准确地通过过滤函数来筛选这些样本。
所以,简而言之,训练数据生成:
可以被理解为拒绝采样
可能在更好的模型带来更好的数据,反之亦然的情况下,创建一个紧密的正反馈环
可能在某些领域中,通过略微改变分布,换取几乎无穷的数据
你对使用语言模型生成训练数据的方法有何看法?你认为这种方法在数据生成和应用中是否有必要?请在评论区分享你的观点和想法。
推荐阅读:
▶GPT-4 被曝“变蠢”!为了降本,OpenAI 偷偷搞“小动作”?
▶马斯克再创业,高调挑战 OpenAI,挖角 DeepMind、微软等 11 位顶级 AI 人才坐镇!
▶ChatGPT 最强竞争对手 Claude 2 推出公开 Beta 版,我们上手实测了一把!

好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论