百度ERNIE 3.0——中文情感分析实战

2023-07-15 18:23:53 545浏览
目录
前言
ERNIE(Enhanced Representation through kNowledge IntEgration)是百度研发的一种基于深度学习的预训练语言模型。它通过大规模的无监督学习从大量文本数据中学习语义和知识表示。一、百度ERNIE 3.0
百度与鹏城自然语言处理联合实验室重磅发布鹏城-百度·文心(模型版本号:ERNIE 3.0 Titan),该模型是全球首个知识增强的千亿AI大模型,也是目前为止全球最大的中文单体模型。
基于业界领先的鹏城实验室算力系统“鹏城云脑Ⅱ”和百度飞桨深度学习平台强强练手,鹏城-百度·文心模型参数规模超越GPT-3达到2600亿,致力于解决传统AI模型泛化性差、强依赖于昂贵的人工标注数据、落地成本高等应用难题,降低AI开发与应用门槛。目前该模型在60多项任务取得最好效果,并大幅刷新小样本学习任务基准。
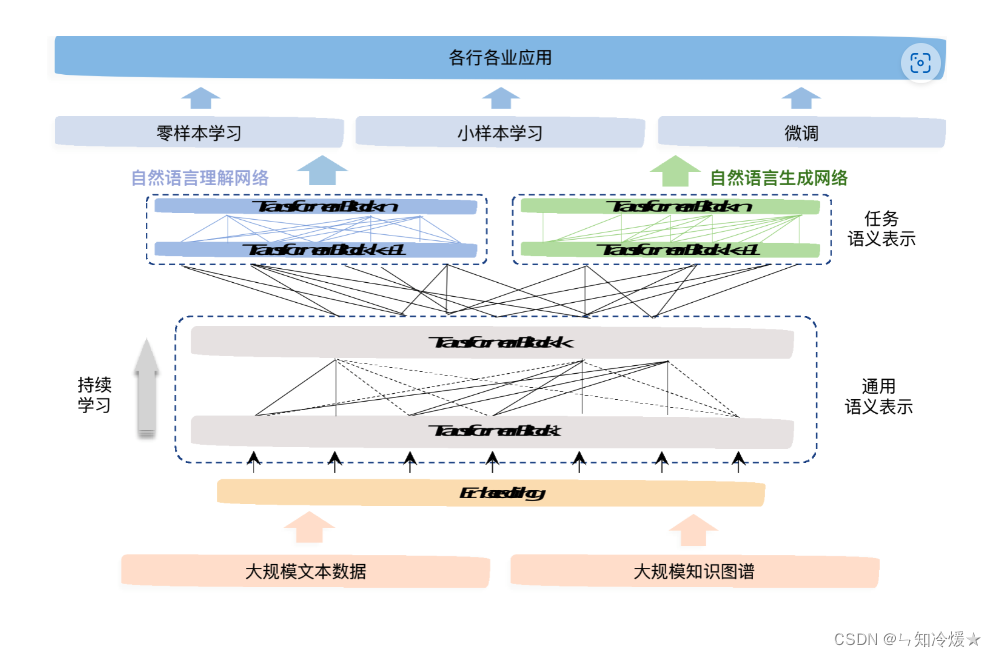
鹏城-百度·文心基于百度知识增强大模型ERNIE 3.0全新升级,模型参数规模达到2600亿,相对GPT-3的参数量提升50%。
在算法框架上,该模型沿袭了ERNIE 3.0的海量无监督文本与大规模知识图谱的平行预训练算法,模型结构上使用兼顾语言理解与语言生成的统一预训练框架。为提升模型语言理解与生成能力,研究团队进一步设计了可控和可信学习算法。
在训练上,结合百度飞桨自适应大规模分布式训练技术和“鹏城云脑Ⅱ”算力系统,解决了超大模型训练中多个公认的技术难题。在应用上,首创大模型在线蒸馏技术,大幅降低了大模型落地成本。
以下为百度-文心模型结构图:
二、使用ERNIE 3.0中文预训练模型进行句子级别的情感分析
2-1、环境
pip install paddle -i https://mirror.baidu.com/pypi/simple
pip install paddlenlp -i https://mirror.baidu.com/pypi/simple
2-2、数据集加载
chnsenticorp: ChnSentiCorp是中文句子级情感分类数据集,包含酒店、笔记本电脑和书籍的网购评论
import os
import paddle
import paddlenlp
#加载中文评论情感分析语料数据集ChnSentiCorp
from paddlenlp.datasets import load_dataset
# 分割训练集验证集和测试集
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
print("训练集样例:", train_ds[0])
输出:
训练集样例: {‘text’: ‘选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般’, ‘label’: 1, ‘qid’: ‘’}
2-3、加载预训练模型和分词器
加载预训练模型和分词器: PaddleNLP中Auto模块(包括AutoModel, AutoTokenizer及各种下游任务类)提供了方便易用的接口,无需指定模型类别,即可调用不同网络结构的预训练模型。PaddleNLP的预训练模型可以很容易地通过from_pretrained()方法加载,Transformer预训练模型汇总包含了40多个主流预训练模型,500多个模型权重。
AutoModelForSequenceClassification可用于句子级情感分析和目标级情感分析任务,通过预训练模型获取输入文本的表示,之后将文本表示进行分类。PaddleNLP已经实现了ERNIE 3.0预训练模型,可以通过一行代码实现ERNIE 3.0预训练模型和分词器的加载。
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "ernie-3.0-medium-zh"
# 预训练模型加载
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_classes=len(train_ds.label_list))
# 分词器加载
tokenizer = AutoTokenizer.from_pretrained(model_name)
2-4、基于预训练模型的数据处理
Dataset中通常为原始数据,需要经过一定的数据处理并进行采样组batch。
- 通过Dataset的map函数,使用分词器将数据集从原始文本处理成模型的输入。
- 定义paddle.io.BatchSampler和collate_fn构建 paddle.io.DataLoader。
实际训练中,根据显存大小调整批大小batch_size和文本最大长度max_seq_length。
import functools
import numpy as np
from paddle.io import DataLoader, BatchSampler
from paddlenlp.data import DataCollatorWithPadding
# 数据预处理函数,利用分词器将文本转化为整数序列
def preprocess_function(examples, tokenizer, max_seq_length, is_test=False):
# 使用分词器处理训练集,给定最大长度。
result = tokenizer(text=examples["text"], max_seq_len=max_seq_length)
if not is_test:
# 如果不是测试集的话,赋予标签,否则不给标签。
result["labels"] = examples["label"]
return result
# 映射到训练集和验证集上。
trans_func = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=128)
train_ds = train_ds.map(trans_func)
dev_ds = dev_ds.map(trans_func)
# collate_fn函数构造,将不同长度序列充到批中数据的最大长度,再将数据堆叠
collate_fn = DataCollatorWithPadding(tokenizer)
# 定义BatchSampler,选择批大小和是否随机乱序,进行DataLoader
train_batch_sampler = BatchSampler(train_ds, batch_size=32, shuffle=True)
dev_batch_sampler = BatchSampler(dev_ds, batch_size=64, shuffle=False)
train_data_loader = DataLoader(dataset=train_ds, batch_sampler=train_batch_sampler, collate_fn=collate_fn)
dev_data_loader = DataLoader(dataset=dev_ds, batch_sampler=dev_batch_sampler, collate_fn=collate_fn)
2-5、数据训练和评估
数据训练和评估: 定义训练所需的优化器、损失函数、评论指标等,就可以开始进行预训练模型的微调任务。
# Adam优化器、交叉熵损失函数、accuracy评价指标
optimizer = paddle.optimizer.AdamW(learning_rate=2e-5, parameters=model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
开始训练:
# 开始训练
import time
import paddle.nn.functional as F
from eval import evaluate
epochs = 5 # 训练轮次
ckpt_dir = "ernie_ckpt" #训练过程中保存模型参数的文件夹
best_acc = 0
best_step = 0
global_step = 0 #迭代次数
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch['input_ids'], batch['token_type_ids'], batch['labels']
# 计算模型输出、损失函数值、分类概率值、准确率
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
# 每迭代10次,打印损失函数值、准确率、计算速度
global_step += 1
if global_step % 10 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
# 每迭代100次,评估当前训练的模型、保存当前模型参数和分词器的词表等
if global_step % 100 == 0:
save_dir = ckpt_dir
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print(global_step, end=' ')
acc_eval = evaluate(model, criterion, metric, dev_data_loader)
if acc_eval > best_acc:
best_acc = acc_eval
best_step = global_step
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)
2-6、模型验证
from eval import evaluate
# 加载ERNIR 3.0最佳模型参数
params_path = 'ernie_ckpt/model_state.pdparams'
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
# 也可以选择加载预先训练好的模型参数结果查看模型训练结果
# model.set_dict(paddle.load('ernie_ckpt_trained/model_state.pdparams'))
print('ERNIE 3.0-Medium 在ChnSentiCorp的dev集表现', end=' ')
eval_acc = evaluate(model, criterion, metric, dev_data_loader)
2-7、情感分析结果的预测以及保存
测试集数据预处理
# 测试集数据预处理,利用分词器将文本转化为整数序列
trans_func_test = functools.partial(preprocess_function, tokenizer=tokenizer, max_seq_length=128, is_test=True)
test_ds_trans = test_ds.map(trans_func_test)
# 进行采样组batch
collate_fn_test = DataCollatorWithPadding(tokenizer)
test_batch_sampler = BatchSampler(test_ds_trans, batch_size=32, shuffle=False)
test_data_loader = DataLoader(dataset=test_ds_trans, batch_sampler=test_batch_sampler, collate_fn=collate_fn_test)
模型预测分类结果
# 模型预测分类结果
import paddle.nn.functional as F
label_map = {0: '负面', 1: '正面'}
results = []
model.eval()
for batch in test_data_loader:
input_ids, token_type_ids = batch['input_ids'], batch['token_type_ids']
logits = model(batch['input_ids'], batch['token_type_ids'])
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
preds = [label_map[i] for i in idx]
results.extend(preds)
预测结果写入excel
# 存储ChnSentiCorp预测结果
test_ds = load_dataset("chnsenticorp", splits=["test"])
res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
with open(os.path.join(res_dir, "ChnSentiCorp.tsv"), 'w', encoding="utf8") as f:
f.write("qid\ttext\tprediction\n")
for i, pred in enumerate(results):
f.write(test_ds[i]['qid']+"\t"+test_ds[i]['text']+"\t"+pred+"\n")
三、自定义个人案例
3-1、如何自定义数据集
众所周知:加载入模型的数据集格式为<class ‘paddlenlp.datasets.dataset.MapDataset’>,在导入个人数据集时,需要首先转换一下数据格式。
from paddlenlp.datasets import load_dataset
# 读取数据,将数据集拆解、重组。
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
# 跳过列名
next(f)
for line in f:
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
yield {'tokens': words, 'labels': labels}
# data_path为read()方法的参数,构建成 MapDataset格式,MapDataset 在绝大多数时候都可以满足要求。
map_ds = load_dataset(read, data_path='train.txt',lazy=False)
# 之后使用train_test_split分割数据集以及使用MapDataset来转换数据格式
# lazy=True参数将数据构建成IterDataset格式,一般只有在数据集过于庞大无法一次性加载进内存的时候我们才考虑使用 IterDataset 。
iter_ds = load_dataset(read, data_path='train.txt',lazy=True)
参考文章:
解析全球最大中文单体模型鹏城-百度·文心技术细节.
源代码地址.
如何自定义数据集.
总结
导入到本地的过程中,发现其中的一个包from eval import evaluate无法导入,盲猜这是paddle的本地类,如果是这样的话,那么只能在百度的平台训练,之后导出模型到本地进行部署了。??
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论