【论文笔记】KDD2019 | KGAT: Knowledge Graph Attention Network for Recommendation

标签: 【论文笔记】KDD2019 | KGAT: Knowledge Graph Attention Network for Recommendation
2023-07-29 18:23:27 518浏览

Abstract
为了更好的推荐,不仅要对user-item交互进行建模,还要将关系信息考虑进来
传统方法因子分解机将每个交互都当作一个独立的实例,但是忽略了item之间的关系(eg:一部电影的导演也是另一部电影的演员)
高阶关系:用一个/多个链接属性连接两个item
KG+user-item graph+high order relations—>KGAT
递归传播邻域节点(可能是users、items、attributes)的嵌入来更新自身节点的嵌入,并使用注意力机制来区分邻域节点的重要性
Introduction

u 1 u_1 u1是要向其提供推荐的目标用户。黄色圆圈和灰色圆圈表示通过高阶关系发现但被传统方法忽略的重要用户和项目。
例如,用户 u 1 u_1 u1看了 电影 i 1 i_1 i1,CF方法侧重于同样观看了 i 1 i_1 i1的相似用户的历史,即 u 4 u_4 u4和 u 5 u_5 u5,而监督学习侧重于与 i 1 i_1 i1有相同属性 e 1 e_1 e1的电影 i 2 i_2 i2,显然,这两种信息对于推荐是互补的,但是现有的监督学习未能将这两者统一起来,比如说这里 i 1 i_1 i1和 i 2 i_2 i2的 r 2 r_2 r2属性都是 e 1 e_1 e1,但是它无法通过 r 3 r_3 r3到达 i 3 i_3 i3, i 4 i_4 i4,因为它把它们当成了独立的部分,无法考虑到数据中的高阶关系,比如黄色圈中的用户看了同一个导演 e 1 e_1 e1的其他电影 i 2 i_2 i2,或者灰色圈中的电影也与 e 1 e_1 e1有其他的关系。这些也是作出推荐的重要信息。
u 1 ⟶ r 1 i 1 ⟶ − r 2 e 1 ⟶ r 2 i 2 ⟶ − r 1 { u 2 , u 3 } , u 1 ⟶ r 1 i 1 ⟶ − r 2 e 1 ⟶ r 3 { i 3 , i 4 } , \begin{array}{l} u_{1} \stackrel{r_{1}}{\longrightarrow} i_{1} \stackrel{-r_{2}}{\longrightarrow} e_{1} \stackrel{r_{2}}{\longrightarrow} i_{2} \stackrel{-r_{1}}{\longrightarrow}\left\{u_{2}, u_{3}\right\}, \\ u_{1} \stackrel{r_{1}}{\longrightarrow} i_{1} \stackrel{-r_{2}}{\longrightarrow} e_{1} \stackrel{r_{3}}{\longrightarrow}\left\{i_{3}, i_{4}\right\}, \end{array} u1⟶r1i1⟶−r2e1⟶r2i2⟶−r1{u2,u3},u1⟶r1i1⟶−r2e1⟶r3{i3,i4},
存在问题
利用这种高阶信息是存在挑战的:
1) 与目标用户具有高阶关系的节点随着阶数的增加而急剧增加,这给模型带来了计算压力
2) 高阶关系对预测的贡献不均衡。
为此,论文提出了 Knowledge Graph Attention Network (KGAT) 的模型,它基于节点邻居的嵌入来更新节点的嵌入,并递归地执行这种嵌入传播,以线性时间复杂度捕获高阶连接。另外采用注意力机制来学习传播期间每个邻居的权重。
GNN->KGAT
1、递归嵌入传播,用领域节点嵌入来更新当前节点嵌入
2、使用注意力机制,来学习传播期间每个邻居的权重
优点:
1、与基于路径的方法相比,避免了人工标定路径
2、与基于规则的方法相比,将高阶关系直接融入预测模型
3. 模型框架
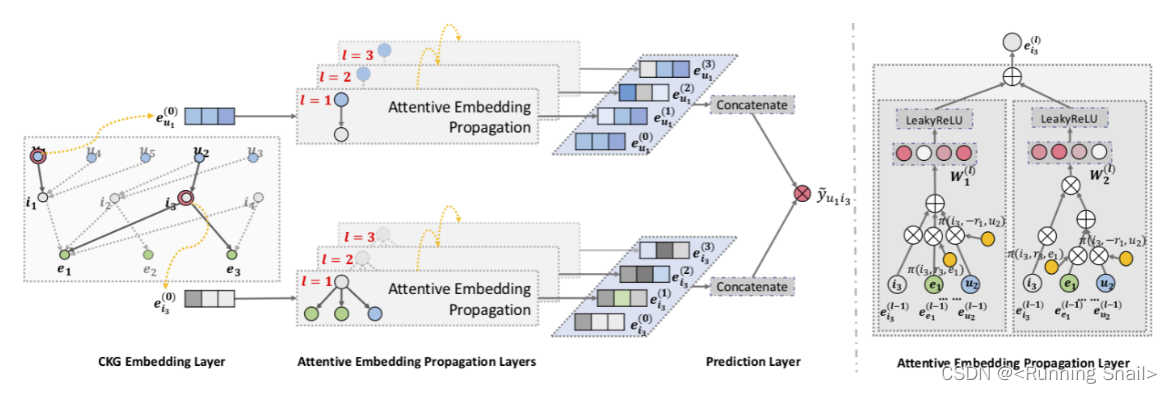
3.1 问题定义
Input:协同知识图 G \mathcal G G, G \mathcal G G由user-item交互数据 G 1 \mathcal G_1 G1和知识图 G 2 \mathcal G_2 G2组成
Output:user u u u点击 item i i i的概率 y ^ u i \hat y_{ui} y^ui
高阶连接:利用高阶连接对于执行高质量的推荐是至关重要的。我们将 L L L阶连接 ( L L L- order connectivtiy) 定义为一个多跳关系路径:
e 0 ⟶ r 1 e 1 ⟶ r 2 . . . ⟶ r L e L e_0 \stackrel {r_1}{\longrightarrow} e_1 \stackrel {r_2}{\longrightarrow} \ ... \ \stackrel {r_L}{\longrightarrow} e_L\\ e0⟶r1e1⟶r2 ... ⟶rLeL
3.2 Embedding Layer
论文在知识图嵌入方面使用了TransR模型,它的主要思想是不同的实体在不同的关系下有着不同的含义,所以需要将实体投影到特定关系空间中,假如 h h h和 t t t具有 r r r关系,那么它们在 r r r关系空间的表示应该接近,否则应该远离,用公式表达则是:
e h r + e r ≈ e t r \mathbf e_h^r + \mathbf e_r \approx \mathbf e_t^r \\ ehr+er≈etr
这里 e h , e t ∈ R d \mathbf e_h, \mathbf e_t \in \mathbb R^d eh,et∈Rd, e r ∈ R k \mathbf e_r \in \mathbb R^k er∈Rk是 h , t , r h ,t ,r h,t,r的embedding。
它的得分为:
g ( h , r , t ) = ∣ ∣ W r e h + e r − W r e t ∣ ∣ 2 2 g(h,r,t)=||\mathbf W_r\mathbf e_h+\mathbf e_r-\mathbf W_r\mathbf e_t||_2^2\\ g(h,r,t)=∣∣Wreh+er−Wret∣∣22
其中 W r ∈ R k × d \mathbf W_r \in \mathbb R^{k\times d} Wr∈Rk×d是关系 r r r的转换矩阵,将实体从 d d d维实体空间投影到 k k k维关系空间中。 g ( h , r , t ) g(h,r,t) g(h,r,t)的值越低,说明该三元组为真的概率越大。
最后,用pairwise ranking loss来衡量效果:
L K G = ∑ ( h , r , t , t ′ ) ∈ τ − l n σ ( g ( h , r , t ′ ) − g ( h , r , t ) ) \mathcal L_{KG} = \sum_{(h,r,t,t^{'})\in \tau} -ln \ \sigma(g(h,r,t^{'})-g(h,r,t))\\ LKG=(h,r,t,t′)∈τ∑−ln σ(g(h,r,t′)−g(h,r,t))
此式子的意思就是让负样本的值减去正样本的值尽可能的大。负样本的选择就是将 t t t随机替换成一个别的。
3.3 Attentive Embedding Propagation Layers
信息传播
考虑实体 h h h,我们使用 N h = { ( h , r , t ) ∣ ( h , r , t ) ∈ G } \mathcal N_h = \{ (h,r,t)|(h,r,t) \in \mathcal G\} Nh={(h,r,t)∣(h,r,t)∈G}表示那些以 h h h为头实体的三元组。计算 h h h的ego-network:
e N h = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t \mathbf e_{\mathcal N_h} = \sum _ {(h,r,t) \in \mathcal N_h} \pi(h,r,t) \mathbf e_t\\ eNh=(h,r,t)∈Nh∑π(h,r,t)et
π ( h , r , t ) \pi(h,r,t) π(h,r,t)表示在关系 r r r下从 t t t传到 h h h的信息量。
知识感知注意力
信息传播中的权重 π ( h , r , t ) \pi(h,r,t) π(h,r,t)是通过注意力机制实现的
π ( h , r , t ) = ( W r e t ) T t a n h ( W r e h + e r ) \pi(h,r,t) = (\mathbf W_r \mathbf e_t)^Ttanh(\mathbf W_r \mathbf e_h+\mathbf e_r)\\ π(h,r,t)=(Wret)Ttanh(Wreh+er)
这里使用 t a n h tanh tanh作为激活函数可以使得在关系空间中越接近的 e h \mathbf e_h eh和 e t \mathbf e_t et有更高的注意力分值。采用 s o f t m a x softmax softmax归一化:
π ( h , r , t ) = e x p ( π ( h , r , t ) ) ∑ ( h , r ′ , t ′ ) ∈ N h e x p ( π ( h , r ′ , t ′ ) ) \pi(h,r,t)=\frac{exp(\pi(h,r,t))}{\sum_{(h,r^{'},t^{'}) \in \mathcal N_h} exp(\pi(h,r^{'},t^{'}))}\\ π(h,r,t)=∑(h,r′,t′)∈Nhexp(π(h,r′,t′))exp(π(h,r,t))
最终凭借 π ( h , r , t ) \pi(h,r,t) π(h,r,t)我们可以知道哪些邻居节点应该被给予更多的关注。
信息聚合
最终将 h h h在实体空间中的表示 e h \mathbf e_h eh和其ego-network的表示 e N h \mathbf e_{\mathcal N_h} eNh聚合起来作为 h h h的新表示:
e h ( 1 ) = f ( e h , e N h ) \mathbf e_h^{(1)} = f(\mathbf e_h,\mathbf e_{\mathcal N_h})\\ eh(1)=f(eh,eNh)
f ( ⋅ ) f(·) f(⋅)有以下几种方式:
- GCN Aggregator:
f G C N = L e a k y R e L U ( W ( e h + e N h ) ) f_{GCN}=LeakyReLU(\mathbf W(\mathbf e_h+\mathbf e_{\mathcal N_h})) fGCN=LeakyReLU(W(eh+eNh)) - GraphSage Aggregator:
f G r a p h S a g e = L e a k y R e L U ( W ( e h ∣ ∣ e N h ) ) f_{GraphSage} = LeakyReLU( \mathbf W(\mathbf e_h || \mathbf e_{\mathcal N_h})) fGraphSage=LeakyReLU(W(eh∣∣eNh)) - Bi-Interaction Aggregator:
f B i − I n t e r a c t i o n = L e a k y R e L U ( W 1 ( e h + e N h ) ) + L e a k y R e L U ( W 2 ( e h ⊙ e N h ) ) f_{Bi-Interaction} = LeakyReLU(\mathbf W_1(\mathbf e_h+\mathbf e_{\mathcal N_h}))+LeakyReLU(\mathbf W_2(\mathbf e_h\odot\mathbf e_{\mathcal N_h})) fBi−Interaction=LeakyReLU(W1(eh+eNh))+LeakyReLU(W2(eh⊙eNh))
高阶传播:
我们可以进一步堆叠更多的传播层来探索高阶连通信息,收集从更高跳邻居传播过来的信息,所以在 l l l步中:
e h ( l ) = f ( e h ( l − 1 ) , e N h ( l − 1 ) ) \mathbf e_h^{(l)} = f( \mathbf e_h^{(l-1)},\mathbf e_{\mathcal N_h}^{(l-1)})\\ eh(l)=f(eh(l−1),eNh(l−1))
其中 e N h ( l − 1 ) = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t ( l − 1 ) \mathbf e_{\mathcal N_h}^{(l-1)} = \sum_{(h,r,t) \in \mathcal N_h} \pi(h,r,t)\mathbf e_t^{(l-1)} eNh(l−1)=∑(h,r,t)∈Nhπ(h,r,t)et(l−1),而 e t ( l − 1 ) \mathbf e_t^{(l-1)} et(l−1)也是通过上面的步骤从 e t 0 \mathbf e_t^0 et0得到的。
3.4 Prediction layer
在执行 L L L层后,最终我们会得到用户 u u u的多层表示: { e u ( 1 ) , . . . , e u ( L ) } \{\mathbf e_u^{(1)},...,\mathbf e_u^{(L)} \} {eu(1),...,eu(L)},以及item i i i的多层表示: { e i ( 1 ) , . . , e i ( L ) } \{\mathbf e_i^{(1)},..,\mathbf e_i^{(L)} \} {ei(1),..,ei(L)}
将其连接起来,即:
e u ∗ = e u ( 0 ) ∣ ∣ . . . ∣ ∣ e u ( L ) , e i ∗ = e i ( 0 ) ∣ ∣ . . . ∣ ∣ e i ( L ) \mathbf e_u^{*} = \mathbf e_u^{(0)} || ...||\mathbf e_u^{(L)} \ ,\ \mathbf e_i^{*} = \mathbf e_i^{(0)} || ...||\mathbf e_i^{(L)} \\ eu∗=eu(0)∣∣...∣∣eu(L) , ei∗=ei(0)∣∣...∣∣ei(L)
最后通过内积计算相关分数:
y ^ ( u , i ) = e u ∗ T e i ∗ \hat y(u,i) = {\mathbf e_u^*}^T \mathbf e_i^*\\ y^(u,i)=eu∗Tei∗
3.5 损失函数
损失函数使用了BPR loss:
L C F = ∑ ( u , i , j ) ∈ O − l n σ ( y ^ ( u , i ) − y ^ ( u , j ) ) \mathcal L_{CF}=\sum_{(u,i,j) \in O} - ln \ \sigma(\hat y(u,i)-\hat y(u,j))\\ LCF=(u,i,j)∈O∑−ln σ(y^(u,i)−y^(u,j))
其中 O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } O = \{(u,i,j)|(u,i) \in \mathcal R^+, (u,j) \in \mathcal R^- \} O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−}, R + \mathcal R^+ R+表示正样本, R − \mathcal R^- R−表示负样本。
最终:
L K G A T = L K G + L C F + λ ∣ ∣ Θ ∣ ∣ 2 2 \mathcal L_{KGAT} = \mathcal L_{KG} + \mathcal L_{CF} + \lambda||\Theta||_2^2\\ LKGAT=LKG+LCF+λ∣∣Θ∣∣22
好博客就要一起分享哦!分享海报
此处可发布评论
评论(0)展开评论
展开评论
您可能感兴趣的博客
